Zookeeper 服务端请求处理流程分析
本章将对 Zookeeper 服务端请求处理流程相关内容进行分析。在 Zookeeper 项目中请求处理核心接口是RequestProcessor,本章将围绕该接口进行分析。
请求处理入口
本节将对 Zookeeper 项目中关于请求处理入口相关内容进行分析,在 Zookeeper 中请求处理的入口是NIOServerCnxn#readPayload方法,在这个方法中会对两种请求类型进行处理,第一种是用于处理建立连接请求,处理方法是readConnectRequest,第二种用于处理操作请求,处理方法是readRequest。本章对请求的处理主要围绕数据操作相关的请求,并不会对连接建立请求进行分析。方法readRequest详细代码如下。
private void readRequest() throws IOException {
zkServer.processPacket(this, incomingBuffer);
}
在上述代码中会调用ZooKeeperServer#processPacket方法完成请求读取操作,ZooKeeperServer#processPacket方法可以将数据包处理分为三大类。
- 请求头类型为安全认证的。
- 请求头类型为SASL认证的。
- 其他请求头类型。
下面先对第一大类安全认证的请求处理进行分析,具体处理代码如下。
if (h.getType() == OpCode.auth) {
LOG.info("got auth packet " + cnxn.getRemoteSocketAddress());
// 创建安全数据包
AuthPacket authPacket = new AuthPacket();
// 将字节缓存中的数据转换为安全数据包对象
ByteBufferInputStream.byteBuffer2Record(incomingBuffer, authPacket);
// 获取安全方案
String scheme = authPacket.getScheme();
// 根据安全方案获取安全验证器
AuthenticationProvider ap = ProviderRegistry.getProvider(scheme);
// 设置安全状态码,第一次设置为安全认证失败
Code authReturn = KeeperException.Code.AUTHFAILED;
if (ap != null) {
try {
// 从安全验证器中获取状态码
authReturn = ap.handleAuthentication(cnxn, authPacket.getAuth());
} catch (RuntimeException e) {
LOG.warn("Caught runtime exception from AuthenticationProvider: " + scheme
+ " due to " + e);
// 安全状态码设置为验证失败
authReturn = KeeperException.Code.AUTHFAILED;
}
}
// 如果是安全状态码是OK则写出响应
if (authReturn == KeeperException.Code.OK) {
if (LOG.isDebugEnabled()) {
LOG.debug("Authentication succeeded for scheme: " + scheme);
}
LOG.info("auth success " + cnxn.getRemoteSocketAddress());
ReplyHeader rh = new ReplyHeader(h.getXid(), 0, KeeperException.Code.OK.intValue());
cnxn.sendResponse(rh, null, null);
}
// 安全状态吗非OK的情况下下
else {
if (ap == null) {
LOG.warn("No authentication provider for scheme: " + scheme + " has "
+ ProviderRegistry.listProviders());
} else {
LOG.warn("Authentication failed for scheme: " + scheme);
}
// 组装响应信息将响应信息发送
ReplyHeader rh =
new ReplyHeader(h.getXid(), 0, KeeperException.Code.AUTHFAILED.intValue());
cnxn.sendResponse(rh, null, null);
// 发送关闭连接
cnxn.sendBuffer(ServerCnxnFactory.closeConn);
// 不再接收数据
cnxn.disableRecv();
}
// 结束处理
return;
}
在上述代码中首先会判断请求头类型是否是OpCode.auth,如果是将会进行如下处理。
- 创建安全数据包(数据包对象为AuthPacket)。
- 将字节缓存中的数据转换为安全数据包对象。底层所使用的技术与Zookeeper中的jute有关。
- 从安全数据包中获取安全方案(安全方案可以理解为认证方案)。
- 根据第(3)步中的安全方案获取安全验证器。
- 创建安全状态码,初始化时将安全状态码设置为(客户端)安全认证失败。
- 如果第(4)步中的安全验证器不为空需要通过安全验证器获取安全验证状态码。如果在安全验证器验证是出现运行时异常,安全验证码设置为安全认证失败。
- 如果第(6)步中的安全验证码是OK的则会写出认证通过的响应,如果是非OK的情况下会发送认证失败响应,发送关闭连接响应并且不再接受数据。
接下来对第二大类SALA安全认证的请求处理进行分析,具体处理代码如下。
private void processSasl(ByteBuffer incomingBuffer, ServerCnxn cnxn,
RequestHeader requestHeader) throws IOException {
LOG.debug("Responding to client SASL token.");
// 创建 SASL 请求对象
GetSASLRequest clientTokenRecord = new GetSASLRequest();
// 将字节缓存中的数据转换为 SASL 请求对象
ByteBufferInputStream.byteBuffer2Record(incomingBuffer, clientTokenRecord);
// 从 SASL 请求对象中获取客户端 token
byte[] clientToken = clientTokenRecord.getToken();
LOG.debug("Size of client SASL token: " + clientToken.length);
// 响应token
byte[] responseToken = null;
try {
// 从服务连接对象中获取 SASL 服务
ZooKeeperSaslServer saslServer = cnxn.zooKeeperSaslServer;
try {
// 通过 SASL 服务创建响应token
responseToken = saslServer.evaluateResponse(clientToken);
// 判断 SASL 服务是否处理完成
if (saslServer.isComplete()) {
// 通过 SASL 服务获取授权id
String authorizationID = saslServer.getAuthorizationID();
LOG.info("adding SASL authorization for authorizationID: " + authorizationID);
// 向服务连接对象中添加安全信息
cnxn.addAuthInfo(new Id("sasl", authorizationID));
// 如果系统环境中zookeeper.superUser属性不为空并且授权id数据和系统环境中zookeeper.superUser的属性相同增加安全信息
if (System.getProperty("zookeeper.superUser") != null &&
authorizationID.equals(System.getProperty("zookeeper.superUser"))) {
cnxn.addAuthInfo(new Id("super", ""));
}
}
}
// 处理过程中出现异常
catch (SaslException e) {
LOG.warn("Client {} failed to SASL authenticate: {}",
cnxn.getRemoteSocketAddress(), e);
// 允许 SASL 认证失败,客户端不需要 SASL 验证,输出警告日志
if (shouldAllowSaslFailedClientsConnect() && !shouldRequireClientSaslAuth()) {
LOG.warn("Maintaining client connection despite SASL authentication failure.");
} else {
// 确认异常值
int error;
// 需要 SASL 验证
if (shouldRequireClientSaslAuth()) {
LOG.warn(
"Closing client connection due to server requires client SASL authenticaiton,"
+
"but client SASL authentication has failed, or client is not configured with SASL "
+
"authentication.");
// 会话关闭 , SASL 认证失败
error = Code.SESSIONCLOSEDREQUIRESASLAUTH.intValue();
} else {
LOG.warn("Closing client connection due to SASL authentication failure.");
// 认证失败
error = Code.AUTHFAILED.intValue();
}
// 组装响应
ReplyHeader replyHeader = new ReplyHeader(requestHeader.getXid(), 0, error);
// 发送响应
cnxn.sendResponse(replyHeader, new SetSASLResponse(null), "response");
// 发送关闭session消息
cnxn.sendCloseSession();
// 不再接收数据
cnxn.disableRecv();
return;
}
}
} catch (NullPointerException e) {
LOG.error(
"cnxn.saslServer is null: cnxn object did not initialize its saslServer properly.");
}
if (responseToken != null) {
LOG.debug("Size of server SASL response: " + responseToken.length);
}
// SASL 验证通过,发送通过信息
ReplyHeader replyHeader = new ReplyHeader(requestHeader.getXid(), 0, Code.OK.intValue());
Record record = new SetSASLResponse(responseToken);
cnxn.sendResponse(replyHeader, record, "response");
}
在上述代码中核心处理流程如下。
- 创建SASL请求对象。
- 将字节缓存中的数据转换为 SASL 请求对象。底层所使用的技术与Zookeeper中的jute有关。
- 从SASL请求对象中获取客户端token,该token将在后续生成响应token时使用。
- 从服务连接对象中获取SASL服务,通过SASL服务创建响应token。在创建响应token后会判断SASL服务是否处理完成,如果处理完成会进行如下操作。
- 通过SASL服务获取授权id。
- 将授权id加入到安全信息中。数据使用ID对象存储,ID方案是sasl,值为授权id。
- 如果系统环境中zookeeper.superUser属性不为空并且4.1中获取的授权id与zookeeper.superUser中的属性值相同将会添加一个新的安全信息,数据ID对象存储,ID方案是super,值为空字符串。
需要注意的是在(3)、(4)步骤中可能会出现异常,具体异常产生是第(3)步的saslServer.evaluateResponse方法,如果出现异常会进行如下操作。
- 如果允许SASL认证失败并且客户端不需要SASL验证将输出警告日志。
- 如果不符合步骤(1)中的条件将进行如下操作。
- 确认异常值,确认规则:如果需要sasl验证将采用SESSIONCLOSEDREQUIRESASLAUTH作为异常值,反之将采用AUTHFAILED作为异常值。
- 组装响应、发送响应、发送关闭session消息、执行不在接收消息命令。
如果SASL验证通过并且没有出现异常将发送通过SASL认证的信息。
最后对其他请求头类型进行分析,具体处理代码如下。
else {
// 需要sasl验证并且未通过sasl验证
if (shouldRequireClientSaslAuth() && !hasCnxSASLAuthenticated(cnxn)) {
// 组装响应信息将响应信息发送
ReplyHeader replyHeader = new ReplyHeader(h.getXid(), 0,
Code.SESSIONCLOSEDREQUIRESASLAUTH.intValue());
cnxn.sendResponse(replyHeader, null, "response");
// 发送session关闭信息
cnxn.sendCloseSession();
// 不再接收数据
cnxn.disableRecv();
}
// 不需要sasl验证或者sasl验证通过
else {
Request si = new Request(cnxn, cnxn.getSessionId(), h.getXid(), h.getType(),
incomingBuffer, cnxn.getAuthInfo());
si.setOwner(ServerCnxn.me);
// 确认是否是本地session如果是将isLocalSession设置为true
setLocalSessionFlag(si);
// 提交请求,进行处理
submitRequest(si);
}
}
在上述代码中核心处理流程如下。
- 如果需要SASL认证并且未通过SASL认证将返回SESSIONCLOSEDREQUIRESASLAUTH异常信息。并且发送session关闭消息以及停止接收数据。
- 不满足步骤(1)的条件判断会进行提交请求操作。
至此终于找到进行请求处理的核心方法submitRequest,下面是具体代码。
public void submitRequest(Request si) {
// 如果首个请求处理器为空
if (firstProcessor == null) {
synchronized (this) {
try {
// 由于所有请求都传递给请求处理器,因此它应该等待设置请求处理器链。设置后状态将更新为 RUNNING。
while (state == State.INITIAL) {
wait(1000);
}
} catch (InterruptedException e) {
LOG.warn("Unexpected interruption", e);
}
if (firstProcessor == null || state != State.RUNNING) {
throw new RuntimeException("Not started");
}
}
}
try {
// 尝试处理 session 相关信息
touch(si.cnxn);
// 验证请求类型
boolean validpacket = Request.isValid(si.type);
// 请求类型验证通过
if (validpacket) {
// 处理请求
firstProcessor.processRequest(si);
// 连接对象存在的情况下
if (si.cnxn != null) {
// 请求处理数量+1
incInProcess();
}
}
// 请求类型验证不通过
else {
LOG.warn("Received packet at server of unknown type " + si.type);
// 用于发送错误码响应的请求处理器
new UnimplementedRequestProcessor().processRequest(si);
}
} catch (MissingSessionException e) {
if (LOG.isDebugEnabled()) {
LOG.debug("Dropping request: " + e.getMessage());
}
} catch (RequestProcessorException e) {
LOG.error("Unable to process request:" + e.getMessage(), e);
}
}
在submitRequest方法中核心处理请求依靠第二个try代码块,执行流程如下。
- 通过touch方法尝试处理session相关信息,处理步骤如下。
- 如果服务连接对象(ServerCnxn)为空则结束处理。
- 从服务连接对象中获取sessionId和session超时时间。
- 通过SessionTracker接口判断sessionId是否存在,如果不存在会返回false,通过SessionTracker接口判断session超时时间是否以超时,如果是会返回false。如果返回值是false将抛出MissingSessionException类型的异常。
- 验证请求是否合法,如果不合法将交给UnimplementedRequestProcessor请求处理器进行处理。如果是合法请求将会交给成员变量firstProcessor进行处理。
在上述处理流程中可以发现对于请求的核心处理流程交给了成员变量firstProcessor,关于成员变量firstProcessor的定义代码如下。
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor syncProcessor = new SyncRequestProcessor(this,
finalProcessor);
((SyncRequestProcessor) syncProcessor).start();
firstProcessor = new PrepRequestProcessor(this, syncProcessor);
((PrepRequestProcessor) firstProcessor).start();
}
在上述代码中可以发现它构造了三种类型的请求处理器,三种类型分别是。
- 最终处理器FinalRequestProcessor。
- 前置处理器(请求准备处理器)PrepRequestProcessor。
- 同步处理器SyncRequestProcessor
在setupRequestProcessors方法中核心是完成请求处理的初始化,对于这个函数的调用时机需要进行阐述,直接调用时机是在ZooKeeperServer#startup方法中,再往外部搜索可以发现该方法的调用时机是在Zookeeper服务启动时,注意Zookeeper服务不区分leader、flower。
至此本节对于Zookeeper中请求处理入口的分析就告一段落,接下来的本章将会对Zookeeper中负责处理请求的各个请求处理器进行分析。
PrepRequestProcessor 分析
本节将对前置处理器(请求准备处理器)PrepRequestProcessor进行分析,该类类图如图所示。
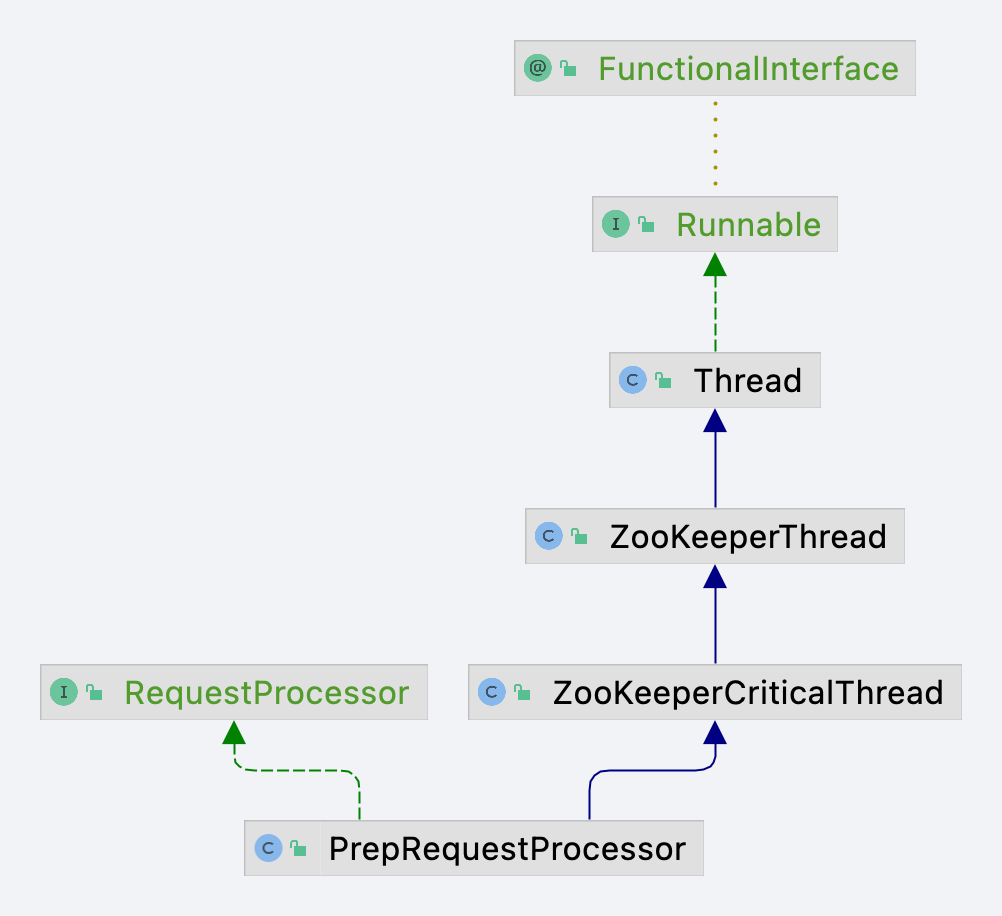
从类图上可以发现它不仅仅实现了请求处理接口(RequestProcessor)还实现了线程相关内容,下面先对请求处理接口的实现进行分析,具体代码如下。
public void processRequest(Request request) {
submittedRequests.add(request);
}
在这段代码中可以发现请求处理的逻辑是将请求对象加入到成员变量submittedRequests,关于成员变量submittedRequests的定义代码如下。
LinkedBlockingQueue<Request> submittedRequests = new LinkedBlockingQueue<Request>();
通过上述代码可以发现存储结构是Queue,存储的行为逻辑完成了,接下来要对它的处理逻辑进行分析,整个请求处理逻辑被封装在线程run方法中,具体处理代码如下。
@Override
public void run() {
try {
// 死循环
while (true) {
// 从成员变量submittedRequests中获取一个请求
Request request = submittedRequests.take();
// 设置跟踪类型为CLIENT_REQUEST_TRACE_MASK
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
// 如果请求类型是ping,将跟踪类型设置为CLIENT_PING_TRACE_MASK
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'P', request, "");
}
// 如果当前请求和死亡请求相同结束死循环停止工作
if (Request.requestOfDeath == request) {
break;
}
// 处理请求
pRequest(request);
}
} catch (RequestProcessorException e) {
if (e.getCause() instanceof XidRolloverException) {
LOG.info(e.getCause().getMessage());
}
// 处理异常
handleException(this.getName(), e);
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("PrepRequestProcessor exited loop!");
}
在上述代码中核心是一个死循环,通过死循环进行请求处理,处理逻辑如下。
- 从成员变量submittedRequests中获取一个请求(从队头获取)。
- 初始化跟踪类型为CLIENT_REQUEST_TRACE_MASK,如果请求类型是ping则设置为CLIENT_PING_TRACE_MASK。然后将其进行日志输出。
- 判断当前请求是否和死亡请求相同,如果是则结束死循环。
- 交给pRequest方法进行正真的请求处理。
在上述处理流程中需要注意异常相关的处理,整个异常处理均交给handleException方法进行。接下来对pRequest方法进行分析,pRequest的处理逻辑可以分为三部分。
- try代码块的执行,这部分会根据不同的请求类型做出不同的操作。
- catch代码块的执行,这部分主要完成在try代码块中出现异常情况下的逻辑处理。
- 下一个请求处理器处理。
接下来先对try代码块中的处理流程进行概述,在try代码块中的处理流程可以概化为如下几个操作步骤。
- 根据不同的请求类型创建不同的请求对象,请求类型和请求对象映射信息见表
- 通过pRequest2Txn方法处理对进行请求和事务之间的转换。
| 请求类型 | 请求对象(Record对象) | 说明 |
|---|---|---|
| OpCode.createContainer、OpCode.create、OpCode.create2 | CreateRequest | 创建类请求。 |
| OpCode.createTTL | CreateTTLRequest | 创建带有过期时间类请求。 |
| OpCode.deleteContainer、OpCode.delete | DeleteRequest | 删除数据类请求。 |
| OpCode.setData | SetDataRequest | 设置数据类请求。 |
| OpCode.reconfig | ReconfigRequest | 重载配置请求。 |
| OpCode.setACL | SetACLRequest | 设置ACL(权限)类请求。 |
| OpCode.check | CheckVersionRequest | 检查版本请求 |
| OpCode.multi | MultiTransactionRecord | 多事务请求。 |
| OpCode.createSession、OpCode.closeSession | 无 | 不做请求转换,非本地session进行pRequest2Txn方法调用。 |
| OpCode.sync、OpCode.exists、OpCode.getData、OpCode.getACL、OpCode.getChildren、OpCode.getChildren2、OpCode.ping、OpCode.setWatches、OpCode.checkWatches、OpCode.removeWatches | 无 | 不做请求转换,交给sessionTracker验证是否合法。 |
了解请求类型和请求对象之间的关系后下面对核心处理方法pRequest2Txn进行分析。该方法的分析按照不同操作类型进行分析。
公共方法分析
在开始进行各个类型的操作之前需要先对PrepRequestProcessor类中提供的一些公共方法进行分析,公共方法有如下五个。
- 方法fixupACL用于计算ACL。
- 方法getRecordForPath用于根据输入路径获取变化档案。
- 方法checkACL用于验证ACL。
- 方法validatePath用于验证路径是否合法。
- 方法addChangeRecord用于添加变化档案。
接下来对fixupACL方法进行分析,具体处理代码如下
private List<ACL> fixupACL(String path, List<Id> authInfo, List<ACL> acls)
throws KeeperException.InvalidACLException {
// 将参数 acls 中重复的数据进行过滤
List<ACL> uniqacls = removeDuplicates(acls);
// 返回结果值存储容器
LinkedList<ACL> rv = new LinkedList<ACL>();
// 如果过滤后的ACL数量为空将抛出异常
if (uniqacls == null || uniqacls.size() == 0) {
throw new KeeperException.InvalidACLException(path);
}
// 遍历过滤后的acl集合
for (ACL a : uniqacls) {
LOG.debug("Processing ACL: {}", a);
// 如果当前元素为空抛出异常
if (a == null) {
throw new KeeperException.InvalidACLException(path);
}
// 提取id
Id id = a.getId();
// id 为空或者id中存储的方案为空抛出异常
if (id == null || id.getScheme() == null) {
throw new KeeperException.InvalidACLException(path);
}
// 如果id中存储的方案是world并且id中的id变量为anyone加入到结果集合中
if (id.getScheme().equals("world") && id.getId().equals("anyone")) {
rv.add(a);
}
// 如果id中存储的方案是auth则进行验证逻辑
else if (id.getScheme().equals("auth")) {
// 身份认证通过标记
boolean authIdValid = false;
for (Id cid : authInfo) {
// 根据安全方案获取安全验证器
AuthenticationProvider ap =
ProviderRegistry.getProvider(cid.getScheme());
if (ap == null) {
LOG.error("Missing AuthenticationProvider for "
+ cid.getScheme());
}
// 通过身份验证
else if (ap.isAuthenticated()) {
authIdValid = true;
rv.add(new ACL(a.getPerms(), cid));
}
}
// 是否认证通过标记为false抛出异常
if (!authIdValid) {
throw new KeeperException.InvalidACLException(path);
}
}
else {
// 根据安全方案获取安全验证器
AuthenticationProvider ap = ProviderRegistry.getProvider(id.getScheme());
// 安全验证器为空或者id验证不通过抛出异常
if (ap == null || !ap.isValid(id.getId())) {
throw new KeeperException.InvalidACLException(path);
}
rv.add(a);
}
}
return rv;
}
在fixupACL方法中核心处理流程如下。
- 将参数acls中的重复数据过滤,留下不重复的数据。
- 创建存储返回结果值的容器。
- 如果过滤后的ACL数量为空将抛出异常。
- 循环过滤重复数据后的acls数据,对单个数据进行如下处理。
- 如果当前元素为空抛出异常。
- 将当前元素中的Id对象提取,如果Id对象为空或者Id对象中存储的方案为空将抛出异常。
- 如果Id对象中存储的方案是world并且Id对象中的id变量为anyone则会将当前元素放入到返回值结果容器中。
- 如果Id对象中存储的方案是auth将进行认证操作。
- 在不满足(3)(4)两种情况下根据安全方案获取安全验证器,如果安全验证器为空或者id验证不通过抛出异常,反之则加入到返回值结果容器中。
在4.4操作流程中会使用到参数authInfo进行认证处理,处理流程如下。
-
创建身份认证通过标记(authIdValid),初始值false。
-
循环处理参数authInfo,对单个数据进行如下操作
- 根据安全方案获取安全验证器。
- 通过安全验证器进行身份验证,如果验证通过则将authIdValid设置为真,并创建ACL对象加入到返回结果值中。
-
如果authIdValid变量为false则抛出异常。
接下来对getRecordForPath方法进行分析,完整代码如下。
private ChangeRecord getRecordForPath(String path) throws KeeperException.NoNodeException {
ChangeRecord lastChange = null;
// 锁住未完成的变化记录
synchronized (zks.outstandingChanges) {
// 从outstandingChangesForPath对象中获取变化档案
lastChange = zks.outstandingChangesForPath.get(path);
if (lastChange == null) {
// 从zk数据库中获取path对应的数据节点
DataNode n = zks.getZKDatabase().getNode(path);
// 如果数据节点不为空
if (n != null) {
Set<String> children;
synchronized (n) {
// 获取当前节点的子节点
children = n.getChildren();
}
// 重写变化档案
lastChange = new ChangeRecord(-1, path, n.stat, children.size(),
zks.getZKDatabase().aclForNode(n));
}
}
}
if (lastChange == null || lastChange.stat == null) {
throw new KeeperException.NoNodeException(path);
}
// 返回
return lastChange;
}
在getRecordForPath方法中需要注意在操作档案的时候是线程安全的,具体操作逻辑如下。
- 从Zookeeper服务对象中获取outstandingChangesForPath变量,然后根据函数参数path获取变化档案。
- 如果变化档案为空将从Zookeeper服务对象中获取zk数据节点然后根据函数参数path获取节点数据。
- 如果第(2)步中获取的节点数据为空将结束处理,不会将将获取当前节点下的子节点然后重新计算档案信息。
- 如果档案信息为空或者档案信息中的状态为空将抛出异常。
在getRecordForPath方法中需要使用到outstandingChangesForPath变量和outstandingChanges变量,这两个变量的定义代码如下。
final Deque<ChangeRecord> outstandingChanges = new ArrayDeque<>();
final HashMap<String, ChangeRecord> outstandingChangesForPath = new HashMap<String, ChangeRecord>();
变量outstandingChanges采用ArrayDeque作为数据存储,存储内容为变化档案(ChangeRecord),变量outstandingChanges采用HashMap作为数据存储,其key表示的是地址(地址在变化档案中存储),value表示的是变化档案(ChangeRecord)。这两个变量的数据会依赖addChangeRecord方法进行数据设置,具体处理代码如下。
private void addChangeRecord(ChangeRecord c) {
synchronized (zks.outstandingChanges) {
zks.outstandingChanges.add(c);
zks.outstandingChangesForPath.put(c.path, c);
}
}
接下来将对checkACL方法进行分析,具体处理代码如下。
static void checkACL(ZooKeeperServer zks, List<ACL> acl, int perm,
List<Id> ids) throws KeeperException.NoAuthException {
// 跳过acl认证
if (skipACL) {
return;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Permission requested: {} ", perm);
LOG.debug("ACLs for node: {}", acl);
LOG.debug("Client credentials: {}", ids);
}
// acl集合为空或acl数量为空
if (acl == null || acl.size() == 0) {
return;
}
// 处理id集合
for (Id authId : ids) {
// 如果id集合中的元素中有一个方案是super返回
if (authId.getScheme().equals("super")) {
return;
}
}
// 处理acl集合
for (ACL a : acl) {
Id id = a.getId();
if ((a.getPerms() & perm) != 0) {
// 方案是world并且id数据为anyone就放行
if (id.getScheme().equals("world")
&& id.getId().equals("anyone")) {
return;
}
// 根据安全方案获取安全验证器
AuthenticationProvider ap = ProviderRegistry.getProvider(id
.getScheme());
// 安全验证器不为空
if (ap != null) {
// 处理参数ids
for (Id authId : ids) {
// 当前id中的方案是否和acl中id的方案相同
// 安全认证器对当前id和acl中的id进行匹配判断
if (authId.getScheme().equals(id.getScheme())
&& ap.matches(authId.getId(), id.getId())) {
return;
}
}
}
}
}
// 抛出异常
throw new KeeperException.NoAuthException();
}
在上述代码中核心处理流程如下。
- 判断是否需要跳过acl认证,如果需要跳过则结束处理。
- 如果参数acl为空或者acl中元素数量为0将结束处理。
- 循环参数acl集合,对单个ACL对象进行如下操作:
- 获取当前ACL对象中的Id对象。
- 将当前ACL中的权限值与方法参数中的权限值进行与操作,如果操作结果不为0则跳过处理。
- 判断ACL对象中Id对象中的方案是否是world,以及id数据是否是anyone,如果这两个条件都满足则结束处理。
- 根据ACL对象中Id对象中的方案获取安全验证器。
- 如果安全验证器不为空则循环处理参数ids,如果满足以下两个条件则结束处理。
- 当前id中的方案是否和acl中id的方案相同。
- 安全认证器对当前id和acl中的id进行匹配判断。
- 如果上述处理流程中并没有结束处理则说明ACL验证失败将抛出异常。
最后对validatePath方法进行分析,具体处理代码如下。
private void validatePath(String path, long sessionId) throws BadArgumentsException {
try {
PathUtils.validatePath(path);
} catch (IllegalArgumentException ie) {
LOG.info("Invalid path {} with session 0x{}, reason: {}",
path, Long.toHexString(sessionId), ie.getMessage());
throw new BadArgumentsException(path);
}
}
在上述代码中会将验证过程交给PathUtils.validatePath方法进行,代码内容较多不做代码贴图,在PathUtils.validatePath方法中对于合法路径的评判标准如下:
- 变量path不能为空。
- 变量path长度不能为0。
- 变量path第一个字符是斜杠("/")。
- 变量path长度为1并且满足前三项。
- 变量path最后一个字符不能是斜杠("/")。
在上述五项基础标准通过的情况下会对整个路径中的字符进行验证,如果满足下面条件中的任意一个就认为是不合法的。
-
当前字符为char c = 0。
-
当前字符为写个,并且最后一个字符也为斜杠。
-
在当前字符为点,并且最后一个字符为点前提下倒数第二个字符为斜杠并且当前字符后一个字符为斜杠。
-
在当前字符为点的情况下,当前字符的前一个字符为斜杠并且当前字符的后一个字符为斜杠。
-
当前字符在如下范围内。
c > '\u0000' && c <= '\u001f' || c >= '\u007f' && c <= '\u009F' || c >= '\ud800' && c <= '\uf8ff' || c >= '\ufff0' && c <= '\uffff'
在了解这五个公共方法后对于后续其他方法的分析会更加清晰。
创建操作
本节将对创建操作进行分析,创建操作主要是由pRequest2TxnCreate方法进行的,核心处理代码如下。
private void pRequest2TxnCreate(int type, Request request, Record record, boolean deserialize)
throws IOException, KeeperException {
// 是否需要反序列化,如果需要则将请求转换到record中
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, record);
}
// 标记,该标记表示了创建类型
int flags;
// 节点地址
String path;
// 权限信息
List<ACL> acl;
// 数据信息
byte[] data;
// 过期时间
long ttl;
// 类型为创建具备过期时间的节点
if (type == OpCode.createTTL) {
CreateTTLRequest createTtlRequest = (CreateTTLRequest) record;
flags = createTtlRequest.getFlags();
path = createTtlRequest.getPath();
acl = createTtlRequest.getAcl();
data = createTtlRequest.getData();
ttl = createTtlRequest.getTtl();
}
else {
CreateRequest createRequest = (CreateRequest) record;
flags = createRequest.getFlags();
path = createRequest.getPath();
acl = createRequest.getAcl();
data = createRequest.getData();
ttl = -1;
}
// 将 flags 转换为创建类型
CreateMode createMode = CreateMode.fromFlag(flags);
// 验证创建请求是否合法
validateCreateRequest(path, createMode, request, ttl);
// 验证创建地址
String parentPath = validatePathForCreate(path, request.sessionId);
// 处理ACL
List<ACL> listACL = fixupACL(path, request.authInfo, acl);
// 获取父节点的数据记录
ChangeRecord parentRecord = getRecordForPath(parentPath);
// 验证ACL
checkACL(zks, parentRecord.acl, ZooDefs.Perms.CREATE, request.authInfo);
// 获取父节点的cversion(创建版本号)
int parentCVersion = parentRecord.stat.getCversion();
// 是否是顺序创建
if (createMode.isSequential()) {
path = path + String.format(Locale.ENGLISH, "%010d", parentCVersion);
}
// 验证路径是否合法
validatePath(path, request.sessionId);
try {
// 如果当前路径已经存在相关档案抛出异常
if (getRecordForPath(path) != null) {
throw new KeeperException.NodeExistsException(path);
}
} catch (KeeperException.NoNodeException e) {
}
// 是否是临时节点
boolean ephemeralParent =
EphemeralType.get(parentRecord.stat.getEphemeralOwner()) == EphemeralType.NORMAL;
if (ephemeralParent) {
throw new KeeperException.NoChildrenForEphemeralsException(path);
}
// 计算新的创建版本号
int newCversion = parentRecord.stat.getCversion() + 1;
// 如果操作类型是创建容器则将txn设置为CreateContainerTxn
if (type == OpCode.createContainer) {
request.setTxn(new CreateContainerTxn(path, data, listACL, newCversion));
}
// 如果操作类型是创建过期节点则将txn设置为CreateTTLTxn
else if (type == OpCode.createTTL) {
request.setTxn(new CreateTTLTxn(path, data, listACL, newCversion, ttl));
}
// 其他创建相关的操作类型将txn设置为CreateTxn
else {
request.setTxn(new CreateTxn(path, data, listACL, createMode.isEphemeral(),
newCversion));
}
StatPersisted s = new StatPersisted();
if (createMode.isEphemeral()) {
s.setEphemeralOwner(request.sessionId);
}
// 拷贝父节点数据
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
// 父节点中子节点数量加一
parentRecord.childCount++;
// 设置创建版本号
parentRecord.stat.setCversion(newCversion);
// 添加变化档案
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.getHdr().getZxid(), path, s, 0, listACL));
}
在上述代码中核心处理流程如下。
- 判断是否需要反序列化,如果需要则将请求转换到参数record中。
- 根据不同类型从record中获取获取flags、path、acl、data和ttl数据。
- 将flags转换为创建类型(CreateMode),创建类型包含如下几种。
- PERSISTENT:持久化类型(持久化节点),该节点除删除命令外不会消失。
- PERSISTENT_SEQUENTIAL:顺序持久化类型(顺序持久化节点),该类型与PERSISTENT具备相同特征,并且增加顺序特征。
- EPHEMERAL:临时类型(临时节点),客户端断开连接后节点将摧毁。
- EPHEMERAL_SEQUENTIAL:顺序临时类型(顺序临时节点),该类型与EPHEMERAL具备相同特征,并且增加顺序特征。
- CONTAINER:容器类型(容器节点),该类型的节点下如果没有子节点将会进行清理操作,操作间隔60秒。
- PERSISTENT_WITH_TTL:带有过期时间的持久化类型。
- PERSISTENT_SEQUENTIAL_WITH_TTL:带有过期时间的顺序持久化类型。
- 通过validateCreateRequest方法验证创建请求是否合法。
- 通过validatePathForCreate方法验证地址是否合法,如果合法将会计算地址。
- 通过fixupACL方法计算ACL。
- 通过getRecordForPath方法获取父地址的变化档案信息(ChangeRecord)。
- 通过checkACL方法验证ACL。
- 提取父节点的cversion数据信息。
- 将第(3)步中的得到的创建类型进行判断,如果是顺序创建的则需要将地址进行重写计算,运算规则:地址+父节点的cversion。
- 通过validatePath方法验证路径是否合法。
- 通过getRecordForPath方法确认路径是否存在相关档案,如果存在档案将抛出异常。
- 判断父节点是否是一个临时节点,如果是则抛出异常。
- 计算新的版本号,计算规则是cversion数据值加一。
- 根据不同的类型设置txn数据信息。
- 创建StatPersisted对象,如果创建类型是临时的将对StatPersisted对象设置sessionId。
- 拷贝父节点数据,为父节点中的子节点数量加一,设置新版本号(cversion)。
- 通过addChangeRecord方法添加变化档案。
通过上述18个操作可以完成节点创建,接下来要对这18个方法中的部分方法做拓展说明,首先是validateCreateRequest方法,该方法用于验证创建请求是否合法,具体处理代码如下。
private void validateCreateRequest(String path,
CreateMode createMode,
Request request,
long ttl)
throws KeeperException {
// 创建模型是否是TTL的
// 是否启用临时节点的拓展属性
if (createMode.isTTL() && !EphemeralType.extendedEphemeralTypesEnabled()) {
throw new KeeperException.UnimplementedException();
}
try {
// 验证TTL是否合法
EphemeralType.validateTTL(createMode, ttl);
} catch (IllegalArgumentException e) {
throw new BadArgumentsException(path);
}
// 创建模型属于临时的
if (createMode.isEphemeral()) {
// 请求中是否携带异常
if (request.getException() != null) {
throw request.getException();
}
// 会话跟踪器验证会话
zks.sessionTracker.checkGlobalSession(request.sessionId,
request.getOwner());
}
else {
// 会话跟踪器验证会话
zks.sessionTracker.checkSession(request.sessionId,
request.getOwner());
}
}
在上述代码中验证逻辑如下。
- 如果创建模型是TTL(存在过期时间的)并且没有启用临时节点的拓展属性将抛出异常,即请求不合法。
- 通过EphemeralType.validateTTL方法验证TTL是否合法,验证的内容是过期时间是否在0-最大范围内。如果不在将抛出异常,即请求不合法。
- 如果创建模型是属于临时的(创建临时节点),判断请求对象中是否存在异常对象,如果存在则抛出异常。如果请求对象中没有携带异常对象将交给会话跟踪器进行验证(验证方法checkGlobalSession)。如果创建模型不属于临时的将直接交给会话跟踪器进行验证(验证方法checkSession)。
最后对validatePathForCreate方法进行分析,该方法用于对创建路径进行验证,具体代码如下。
private String validatePathForCreate(String path, long sessionId)
throws BadArgumentsException {
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1 || path.indexOf('\0') != -1 || failCreate) {
LOG.info("Invalid path %s with session 0x%s",
path, Long.toHexString(sessionId));
throw new KeeperException.BadArgumentsException(path);
}
return path.substring(0, lastSlash);
}
在上述代码中会完成两个操作。
- 判断路径是否合法。合法标准如下。
- 存在斜杠。
- 不存在字符'\0'
- 返回当前路径的父路径。
删除容器操作
本节将对删除容器操作进行分析,删除容器的操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.deleteContainer: {
// 提取请求中的路径
String path = new String(request.request.array());
// 提取父路径
String parentPath = getParentPathAndValidate(path);
// 父节点档案信息
ChangeRecord parentRecord = getRecordForPath(parentPath);
// 当前节点档案信息
ChangeRecord nodeRecord = getRecordForPath(path);
// 当前节点存在子节点抛出异常
if (nodeRecord.childCount > 0) {
throw new KeeperException.NotEmptyException(path);
}
if (EphemeralType.get(nodeRecord.stat.getEphemeralOwner())
== EphemeralType.NORMAL) {
throw new KeeperException.BadVersionException(path);
}
// 设置 txn
request.setTxn(new DeleteTxn(path));
// 拷贝父节点数据
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
// 父节点的子节点数量减一
parentRecord.childCount--;
// 添加变化档案
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.getHdr().getZxid(), path, null, -1, null));
break;
}
在上述代码中主要处理流程如下。
- 提取请求对象中的路径。
- 将请求对象中的路径进行验证,并且提取父路径。
- 通过getRecordForPath方法获取父路径的档案和当前路径的档案。
- 如果当前档案中的子节点数量大于0则抛出异常。
- 获取当前节点的临时拥有者数据,将拥有者数据转换为EphemeralType对象,如果转换结果是NORMAL将抛出异常。
- 为请求设置txn数据,具体类型是DeleteTxn。
- 拷贝父节点的数据,将父节点数据中的子节点数量减一。
- 通过 addChangeRecord方法将父节点档案和当前节点的变更档案加入到档案容器中。
删除节点操作
本节将对删除节点操作进行分析,删除节点的操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.delete:
// 通过sessionTracker验证session
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
// 转换为删除请求
DeleteRequest deleteRequest = (DeleteRequest) record;
// 如果需要反序列化请求对象中的信息反序列化到删除请求中
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, deleteRequest);
}
// 获取需要删除的路径
String path = deleteRequest.getPath();
// 获取删除路径的父路径
String parentPath = getParentPathAndValidate(path);
// 获取父路径的档案
ChangeRecord parentRecord = getRecordForPath(parentPath);
// 获取当前路径的档案
ChangeRecord nodeRecord = getRecordForPath(path);
// 验证ACL
checkACL(zks, parentRecord.acl, ZooDefs.Perms.DELETE, request.authInfo);
// 验证版本号
checkAndIncVersion(nodeRecord.stat.getVersion(), deleteRequest.getVersion(), path);
// 当前节点的子节点数量大于0抛出异常
if (nodeRecord.childCount > 0) {
throw new KeeperException.NotEmptyException(path);
}
// 设置txn
request.setTxn(new DeleteTxn(path));
// 拷贝父节点
parentRecord = parentRecord.duplicate(request.getHdr().getZxid());
// 父节点的子节点数量减一
parentRecord.childCount--;
// 加入变化档案
addChangeRecord(parentRecord);
addChangeRecord(new ChangeRecord(request.getHdr().getZxid(), path, null, -1, null));
break;
在上述代码中核心处理流程如下。
- 通过sessionTracker验证session,如果验证不通过将抛出异常。
- 将record变量转换为删除请求对象,如果需要进行反序列化则将请求对象中的数据反序列化到删除请求对象中。
- 从删除请求中获取需要删除的路径,根据需要删除的路径获取父路径,父路径对应的档案,删除路径的档案。
- 通过checkACL方法验证权限。
- 通过checkAndIncVersion方法验证版本号。
- 如果当前节点的子节点数量大于0将会抛出异常,抛出该异常的作用是希望删除是从最低节点开始删除。
- 为请求设置txn数据,具体类型是DeleteTxn。
- 拷贝父节点的数据,将父节点数据中的子节点数量减一。
- 通过 addChangeRecord方法将父节点档案和当前节点的变更档案加入到档案容器中
在上述处理流程中需要关注checkAndIncVersion方法,不仅仅是验证版本号,还会进行版本累加一操作,具体代码如下。
private static int checkAndIncVersion(int currentVersion, int expectedVersion, String path)
throws KeeperException.BadVersionException {
if (expectedVersion != -1 && expectedVersion != currentVersion) {
throw new KeeperException.BadVersionException(path);
}
return currentVersion + 1;
}
在checkAndIncVersion方法中如果同时满足下面两个条件将抛出异常。
- 删除请求中的版本号(expectedVersion,该方法中参数的直接含义为期望版本号,在删除阶段以删除请求中的版本号为实际参数,其他阶段有对应参数意义)不为-1。
- 删除请求中的版本号与当前版本号(currentVersion)不相同。
如果不抛出异常会操作当前版本号,版本号累加一。
设置数据操作
本节将对设置数据操作进行分析,设置数据的操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.setData:
// 通过sessionTracker验证session
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
// 转换为设置数据请求
SetDataRequest setDataRequest = (SetDataRequest) record;
// 如果需要反序列化请求对象中的信息反序列化到设置数据请求中
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, setDataRequest);
}
// 获取当前操作路径
path = setDataRequest.getPath();
// 验证当前操作路径
validatePath(path, request.sessionId);
// 获取当前操作路径对应的档案
nodeRecord = getRecordForPath(path);
// 验证权限
checkACL(zks, nodeRecord.acl, ZooDefs.Perms.WRITE, request.authInfo);
// 计算新的版本
int newVersion = checkAndIncVersion(nodeRecord.stat.getVersion(),
setDataRequest.getVersion(), path);
// 设置txn
request.setTxn(new SetDataTxn(path, setDataRequest.getData(), newVersion));
// 拷贝当前节点的档案
nodeRecord = nodeRecord.duplicate(request.getHdr().getZxid());
// 设置版本号
nodeRecord.stat.setVersion(newVersion);
// 添加变化档案
addChangeRecord(nodeRecord);
break;
在上述代码中核心处理流程如下。
- 通过sessionTracker验证session,如果验证不通过将抛出异常。
- 将record变量转换为设置数据请求对象,如果需要进行反序列化则将请求对象中的数据反序列化到设置数据请求对象中。
- 在设置数据请求对象中提取需要操作的路径。
- 通过validatePath方法验证当前操作路径,验证不通过将抛出异常。
- 通过checkACL方法进行权限验证。
- 通过checkAndIncVersion方法验证版本号并计算新的版本号。
- 为请求设置txn数据,具体类型是SetDataTxn。
- 拷贝当前操作节点的数据,并设置新的版本。
- 通过addChangeRecord方法将当前操作节点的变更档案加入到档案容器中。
重载配置操作
本节将对重载配置操作进行分析,重载配置的操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.reconfig:
// 如果zk服务没有启动配置重载将抛出异常
if (!zks.isReconfigEnabled()) {
LOG.error("Reconfig operation requested but reconfig feature is disabled.");
throw new KeeperException.ReconfigDisabledException();
}
// 如果跳过acl会输出警告日志
if (skipACL) {
LOG.warn("skipACL is set, reconfig operation will skip ACL checks!");
}
// 通过sessionTracker验证session
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
// 转换为重载配置请求
ReconfigRequest reconfigRequest = (ReconfigRequest) record;
// 确认leader服务
LeaderZooKeeperServer lzks;
try {
// 如果当前zk服务无法转换为LeaderZooKeeperServer将抛出异常
lzks = (LeaderZooKeeperServer) zks;
} catch (ClassCastException e) {
throw new KeeperException.UnimplementedException();
}
// 获取最后一个验证器
QuorumVerifier lastSeenQV = lzks.self.getLastSeenQuorumVerifier();
// 最后一个验证器的版本和leader服务中的验证器版本不相等将抛出异常
if (lastSeenQV.getVersion() != lzks.self.getQuorumVerifier().getVersion()) {
throw new KeeperException.ReconfigInProgress();
}
// 获取配置id
long configId = reconfigRequest.getCurConfigId();
// 配置id为-1
// 配置id不等于最后一个验证器的版本
if (configId != -1 && configId != lzks.self.getLastSeenQuorumVerifier()
.getVersion()) {
String msg = "Reconfiguration from version " + configId
+ " failed -- last seen version is " +
lzks.self.getLastSeenQuorumVerifier().getVersion();
throw new KeeperException.BadVersionException(msg);
}
// 获取新成员(配置数据)
String newMembers = reconfigRequest.getNewMembers();
// 新成员不为空
if (newMembers != null) {
LOG.info("Non-incremental reconfig");
newMembers = newMembers.replaceAll(",", "\n");
try {
// 读取新成员数据
Properties props = new Properties();
props.load(new StringReader(newMembers));
// 解析配置
request.qv = QuorumPeerConfig.parseDynamicConfig(props,
lzks.self.getElectionType(), true, false);
request.qv.setVersion(request.getHdr().getZxid());
} catch (IOException | ConfigException e) {
throw new KeeperException.BadArgumentsException(e.getMessage());
}
} else {
LOG.info("Incremental reconfig");
// 求需要进入集群的服务
List<String> joiningServers = null;
String joiningServersString = reconfigRequest.getJoiningServers();
if (joiningServersString != null) {
joiningServers = StringUtils.split(joiningServersString, ",");
}
// 求需要离开的服务
List<String> leavingServers = null;
String leavingServersString = reconfigRequest.getLeavingServers();
if (leavingServersString != null) {
leavingServers = StringUtils.split(leavingServersString, ",");
}
// 类型不同抛出异常
if (!(lastSeenQV instanceof QuorumMaj)) {
String msg =
"Incremental reconfiguration requested but last configuration seen has a non-majority quorum system";
LOG.warn(msg);
throw new KeeperException.BadArgumentsException(msg);
}
// 服务集合
Map<Long, QuorumServer> nextServers =
new HashMap<Long, QuorumServer>(lastSeenQV.getAllMembers());
try {
// 如果需要离开的服务变量存在则将nextServers中对应的数据删除
if (leavingServers != null) {
for (String leaving : leavingServers) {
long sid = Long.parseLong(leaving);
nextServers.remove(sid);
}
}
// 如果需要进入的服务存在则将数据加入到nextServers中
if (joiningServers != null) {
for (String joiner : joiningServers) {
String[] parts =
StringUtils.split(joiner, "=").toArray(new String[0]);
if (parts.length != 2) {
throw new KeeperException.BadArgumentsException(
"Wrong format of server string");
}
Long sid = Long.parseLong(
parts[0].substring(parts[0].lastIndexOf('.') + 1));
QuorumServer qs = new QuorumServer(sid, parts[1]);
if (qs.clientAddr == null || qs.electionAddr == null
|| qs.addr == null) {
throw new KeeperException.BadArgumentsException(
"Wrong format of server string - each server should have 3 ports specified");
}
for (QuorumServer nqs : nextServers.values()) {
if (qs.id == nqs.id) {
continue;
}
qs.checkAddressDuplicate(nqs);
}
nextServers.remove(qs.id);
nextServers.put(qs.id, qs);
}
}
} catch (ConfigException e) {
throw new KeeperException.BadArgumentsException("Reconfiguration failed");
}
// 设置请求参数qv
request.qv = new QuorumMaj(nextServers);
request.qv.setVersion(request.getHdr().getZxid());
}
// 如果仲裁配置启用并且投票成员数量小于2,抛出异常
if (QuorumPeerConfig.isStandaloneEnabled()
&& request.qv.getVotingMembers().size() < 2) {
String msg =
"Reconfig failed - new configuration must include at least 2 followers";
LOG.warn(msg);
throw new KeeperException.BadArgumentsException(msg);
}
// 如果投票成员数量小于1抛出异常
else if (request.qv.getVotingMembers().size() < 1) {
String msg =
"Reconfig failed - new configuration must include at least 1 follower";
LOG.warn(msg);
throw new KeeperException.BadArgumentsException(msg);
}
// 仲裁数据是否同步,如果没有同步抛出异常
if (!lzks.getLeader().isQuorumSynced(request.qv)) {
String msg2 =
"Reconfig failed - there must be a connected and synced quorum in new configuration";
LOG.warn(msg2);
throw new KeeperException.NewConfigNoQuorum();
}
// 获取配置节点的档案
nodeRecord = getRecordForPath(ZooDefs.CONFIG_NODE);
// 验证权限
checkACL(zks, nodeRecord.acl, ZooDefs.Perms.WRITE, request.authInfo);
// 设置txn
request.setTxn(
new SetDataTxn(ZooDefs.CONFIG_NODE, request.qv.toString().getBytes(), -1));
nodeRecord = nodeRecord.duplicate(request.getHdr().getZxid());
nodeRecord.stat.setVersion(-1);
addChangeRecord(nodeRecord);
break;
在上述代码中主要处理流程如下。
-
判断zk服务是否启动配置重载,如果没有则抛出异常。
-
如果需要跳过acl验证将记录警告日志。
-
通过sessionTracker验证session,如果验证不通过将抛出异常。
-
将变量record转换为重载配置请求
-
对变量zks进行类型转换,转换目标是LeaderZooKeeperServer类,如果转换失败将抛出异常。如果转换成功将赋值到变量lzks中。
-
从变量lzks中获取最后一个验证器。
-
从最后一个验证器中获取版本信息,如果版本信息和变量lzks中的验证器版本不相同则抛出异常。该异常表示有正在进行中的重载配置操作。
-
获取重载配置请求中的id,如果id为-1并且id和最后一个验证器中的版本不相同将抛出异常。
-
从请求中获取新成员(变量newMembers,具体数据是配置信息)。
-
如果第(9)步中的新成员不为空将通过QuorumPeerConfig.parseDynamicConfig方法对新成员进行配置解析并将其解析结果放置到请求对象中(request.qv)。
-
如果第(9)步中的新成员为空则进行如下操作。
- 从请求中获取需要进入集群的服务列表和需要离开集群的服务列表。
- 创建服务集合容器,初识化时数据会从Zookeeper服务对象中获取(具体方法lastSeenQV.getAllMembers)。
- 如果需要离开集群的服务列表存在将会在服务集合容器中移除相关内容。
- 如果需要进入集群的服务列表存在将会在服务集合容器中添加相关内容。
- 将服务集合容器转换为QuorumMaj对象并将其设置到请求参数的qv属性中。
-
如果启用仲裁配置但是在请求对象的qv属性中的投票成员数量少于2将抛出异常。亦或者投票成员数量少于一则抛出异常。
-
判断仲裁数据(投票数据)是否同步,如果没有同步将抛出异常。
-
获取配置节点(节点地址:/zookeeper/config)的档案。
-
通过checkACL方法验证权限。
-
为请求设置txn数据,具体类型是SetDataTxn。
-
拷贝配置节点的档案。
-
通过addChangeRecord方法将配置节点的变更档案加入到档案容器中。
设置权限操作
本节将对设置权限操作进行分析,设置权限的操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.setACL:
// 通过sessionTracker验证session
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
// 类型转换
SetACLRequest setAclRequest = (SetACLRequest) record;
// 反序列化
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, setAclRequest);
}
// 获取操作路径
path = setAclRequest.getPath();
// 验证路径
validatePath(path, request.sessionId);
// 计算ACL
List<ACL> listACL = fixupACL(path, request.authInfo, setAclRequest.getAcl());
// 获取当前路径对应的档案
nodeRecord = getRecordForPath(path);
// 校验ACL
checkACL(zks, nodeRecord.acl, ZooDefs.Perms.ADMIN, request.authInfo);
// 计算新版本号
newVersion = checkAndIncVersion(nodeRecord.stat.getAversion(),
setAclRequest.getVersion(), path);
// 设置txn
request.setTxn(new SetACLTxn(path, listACL, newVersion));
// 拷贝当前路径对应的档案
nodeRecord = nodeRecord.duplicate(request.getHdr().getZxid());
nodeRecord.stat.setAversion(newVersion);
addChangeRecord(nodeRecord);
break;
在上述代码中主要处理流程如下。
- 通过sessionTracker验证session,如果验证不通过将抛出异常。
- 将变量record转换为设置权限请求。如果需要反序列化则会将请求对象中的数据反序列化到设置权限请求对象中。
- 从设置权限请求对象中获取操作路径,并对该路径进行验证,如果验证不通过将抛出异常。
- 通过fixupACL方法计算ACL。
- 通过checkAndIncVersion方法计算新版本号。
- 为请求设置txn数据,具体类型是SetACLTxn。
- 拷贝当前节点的档案。
- 通过addChangeRecord方法将当前节点的变更档案加入到档案容器中。
创建session操作
本节将对创建session操作进行分析,创建session操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.createSession:
request.request.rewind();
// 超时时间
int to = request.request.getInt();
request.setTxn(new CreateSessionTxn(to));
request.request.rewind();
// 不同状态设置sessionId
if (request.isLocalSession()) {
zks.sessionTracker.addSession(request.sessionId, to);
} else {
zks.sessionTracker.addGlobalSession(request.sessionId, to);
}
zks.setOwner(request.sessionId, request.getOwner());
break;
在上述代码中关于创建session的操作会分为两种类型。
- 如果请求是本地session将通过addSession方法添加sessionId。
- 如果请求不是本地session将通过addGlobalSession方法添加sessionId。
在添加完成sessionId以后会ZooKeeperServer#setOwner方法将sessionId和所有者进行绑定。
关闭session操作
本节将对关闭session操作进行分析,关闭session操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.closeSession:
// 根据sessionId获取对应的临时路径
Set<String> es = zks.getZKDatabase()
.getEphemerals(request.sessionId);
// 锁
synchronized (zks.outstandingChanges) {
// 循环outstandingChanges对象
for (ChangeRecord c : zks.outstandingChanges) {
// 如果状态为空则
if (c.stat == null) {
// Doing a delete
// 在临时路径集合中删除
es.remove(c.path);
}
// 如果状态的临时拥有者和当前sessionId相同则将其加入到临时路径集合中
else if (c.stat.getEphemeralOwner() == request.sessionId) {
es.add(c.path);
}
}
// 循环进行删除标记
for (String path2Delete : es) {
addChangeRecord(
new ChangeRecord(request.getHdr().getZxid(), path2Delete, null, 0,
null));
}
// 关闭sessionId
zks.sessionTracker.setSessionClosing(request.sessionId);
}
break;
在上述代码中主要处理流程如下。
- 在Zookeeper数据库中搜索当前请求中sessionId对应的临时路径集合。
- 循环zks对象中的outstandingChanges变量,对单个元素进行如下操作。
- 如果当前元素的状态为空则需要在临时路径集合中删除。
- 如果当前元素中状态的临时拥有者属性和请求中的sessionId相同则需要将其加入到临时路径集合中。
- 循环临时路径集合构造变化档案然后将新的档案加入到档案容器中。
- 关闭sessionId。
检查类操作
本节将对检查类操作进行分析,检查类操作并没有封装为一个方法,而是在case代码块中,具体处理代码如下。
case OpCode.check:
// 通过sessionTracker验证session
zks.sessionTracker.checkSession(request.sessionId, request.getOwner());
// 类型转换
CheckVersionRequest checkVersionRequest = (CheckVersionRequest) record;
// 反序列化
if (deserialize) {
ByteBufferInputStream.byteBuffer2Record(request.request, checkVersionRequest);
}
// 提取需要操作路径
path = checkVersionRequest.getPath();
// 验证路径
validatePath(path, request.sessionId);
// 获取操作路径对应的档案
nodeRecord = getRecordForPath(path);
// 验证acl
checkACL(zks, nodeRecord.acl, ZooDefs.Perms.READ, request.authInfo);
// 设置txn
request.setTxn(
new CheckVersionTxn(path, checkAndIncVersion(nodeRecord.stat.getVersion(),
checkVersionRequest.getVersion(), path)));
break;
在上述代码中主要处理流程如下。
- 通过sessionTracker验证session,如果验证不通过将抛出异常。
- 将变量record转换为验证请求。如果需要反序列化则会将请求对象中的数据反序列化到设置验证请求对象中。
- 从验证请求中提取操作路径,对该路径进行验证,如果验证失败将抛出异常。
- 根据当前操作路径获取对应的档案信息。
- 通过checkACL方法验证权限(ACL)。
- 为请求设置txn数据,具体类型是CheckVersionTxn。
多事务请求
接下来将会回到PrepRequestProcessor#pRequest方法对OpCode.multi中类型的操作进行分析,具体处理代码如下。
case OpCode.multi:{
// 创建多事务请求对象
MultiTransactionRecord multiRequest = new MultiTransactionRecord();
try {
// 请求对象转换为多事务请求对象
ByteBufferInputStream.byteBuffer2Record(request.request, multiRequest);
} catch (IOException e) {
// 异常设置头信息
request.setHdr(
new TxnHeader(request.sessionId, request.cxid, zks.getNextZxid(),
Time.currentWallTime(), OpCode.multi));
throw e;
}
List<Txn> txns = new ArrayList<Txn>();
// 获取下一个zxid
long zxid = zks.getNextZxid();
// 异常记录变量
KeeperException ke = null;
// 将多事务请求对象转换为map结构,用于后续回滚操作
Map<String, ChangeRecord> pendingChanges = getPendingChanges(multiRequest);
// 循环处理多事务请求对象
for (Op op : multiRequest) {
// 从单个事务中获取请求信息
Record subrequest = op.toRequestRecord();
// 操作类型
int type;
// 档案信息
Record txn;
// 如果异常记录变量不为空设置异常相关信息
if (ke != null) {
type = OpCode.error;
txn = new ErrorTxn(Code.RUNTIMEINCONSISTENCY.intValue());
}
else {
try {
// 执行核心请求转事务逻辑
pRequest2Txn(op.getType(), zxid, request, subrequest, false);
// 记录操作类型
type = request.getHdr().getType();
// 记录txn
txn = request.getTxn();
}
// 异常相关信息记录
catch (KeeperException e) {
ke = e;
type = OpCode.error;
txn = new ErrorTxn(e.code().intValue());
if (e.code().intValue() > Code.APIERROR.intValue()) {
LOG.info(
"Got user-level KeeperException when processing {} aborting"
+
" remaining multi ops. Error Path:{} Error:{}",
request.toString(), e.getPath(), e.getMessage());
}
request.setException(e);
// 回滚操作
rollbackPendingChanges(zxid, pendingChanges);
}
}
// 输出档案处理
ByteArrayOutputStream baos = new ByteArrayOutputStream();
BinaryOutputArchive boa = BinaryOutputArchive.getArchive(baos);
txn.serialize(boa, "request");
ByteBuffer bb = ByteBuffer.wrap(baos.toByteArray());
txns.add(new Txn(type, bb.array()));
}
request.setHdr(new TxnHeader(request.sessionId, request.cxid, zxid,
Time.currentWallTime(), request.type));
request.setTxn(new MultiTxn(txns));
break;
}
在上述代码中主要处理流程如下。
- 创建多事务请求对象,将请求对象中的数据反序列化到多事务请求对象中。在反序列化过程中如果出现异常将设置请求对象的头信息,并抛出异常。
- 创建Txn数据容器。
- 通过getPendingChanges方法将多事务请求对象转换为Map结构用于后续回滚操作使用。
- 从zk服务对象中获取下一个zxid。
- 创建异常记录变量ex,默认值为null表示没有异常。
- 循环多事务请求对象,对单个事务请求对象进行如下操作。
- 从单个事务请求中获取请求信息(Record)。
- 如果 外部的异常记录变量不为空将设置操作类型为异常,将设置txn对象为ErrorTxn。
- 如果外部的异常记录变量为空则则通过pRequest2Txn方法完成事务操作的处理,在操作完成后记录操作类型和txn,如果在pRequest2Txn方法的处理过程中出现异常将会设置外部异常记录变量为当下出现的异常,并设置操作类型和txn变量。然后通过rollbackPendingChanges方法进行回滚操作。
在上述处理流程中最关键的两个方法分别是pRequest2Txn和rollbackPendingChanges,前者方法在本节前的篇幅中已经做出详细分析,本节主要对后者方法进行分析,完整代码如下。
void rollbackPendingChanges(long zxid, Map<String, ChangeRecord> pendingChangeRecords) {
// 锁
synchronized (zks.outstandingChanges) {
// 遍历outstandingChanges变量
Iterator<ChangeRecord> iter = zks.outstandingChanges.descendingIterator();
while (iter.hasNext()) {
ChangeRecord c = iter.next();
// 如果操作的档案和当前档案相同
if (c.zxid == zxid) {
iter.remove();
zks.outstandingChangesForPath.remove(c.path);
}
else {
break;
}
}
// outstandingChanges变量为空
if (zks.outstandingChanges.isEmpty()) {
return;
}
// 获取第一个zxid
long firstZxid = zks.outstandingChanges.peek().zxid;
// 小于第一个zxid的都跳过处理,大于等于的将其加入到outstandingChangesForPath变量中
for (ChangeRecord c : pendingChangeRecords.values()) {
if (c.zxid < firstZxid) {
continue;
}
zks.outstandingChangesForPath.put(c.path, c);
}
}
}
在上述代码中核心操作流程如下。
- 遍历zk服务对象中的变量outstandingChanges,如果遍历的单个元素zxid和当前需要处理的zxid相同则需要将这个元素从outstandingChanges中移除,同时也需要将outstandingChangesForPath变量中的数据根据路径移除。
- 如果zk服务对象中的变量outstandingChanges为空则结束处理。
- 从zk服务对象中的outstandingChanges变量提取第一个zxid。
- 循环方法参数pendingChangeRecords,如果其中的元素zxid小于第(3)步中提取的zxid将跳过处理,反之则将其加入到outstandingChangesForPath变量中。
LeaderRequestProcessor 分析
本节将对领导者请求处理器LeaderRequestProcessor进行分析,它的作用是负责处理领导者相关的请求,在LeaderRequestProcessor类中存在两个成员变量详细信息见表。
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| lzks | LeaderZooKeeperServer | Zookeeper的领导者服务。 |
| nextProcessor | RequestProcessor | 下一个请求处理器 |
了解成员变量后下面需要了解构造函数的使用,构造函数代码如下。
public LeaderRequestProcessor(LeaderZooKeeperServer zks,
RequestProcessor nextProcessor) {
this.lzks = zks;
this.nextProcessor = nextProcessor;
}
在构造函数中会需要传输两个变量,这两个变量的具体构造过程在LeaderZooKeeperServer#setupRequestProcessors方法中,具体处理代码如下。
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor toBeAppliedProcessor =
new Leader.ToBeAppliedRequestProcessor(finalProcessor, getLeader());
commitProcessor = new CommitProcessor(toBeAppliedProcessor,
Long.toString(getServerId()), false,
getZooKeeperServerListener());
commitProcessor.start();
ProposalRequestProcessor proposalProcessor = new ProposalRequestProcessor(this,
commitProcessor);
proposalProcessor.initialize();
prepRequestProcessor = new PrepRequestProcessor(this, proposalProcessor);
prepRequestProcessor.start();
firstProcessor = new LeaderRequestProcessor(this, prepRequestProcessor);
setupContainerManager();
}
在上述代码中重点关注LeaderRequestProcessor的构造函数,在其中会使用this表示构造函数中第一个参数,变量prepRequestProcessor表示构造函数中第二个参数。此时可以明确在LeaderRequestProcessor类中nextProcessor变量的实际数据类型是PrepRequestProcessor。
了解成员变量的具体数据类型后对LeaderRequestProcessor类中的processRequest方法进行分析,具体处理代码如下。
@Override
public void processRequest(Request request)
throws RequestProcessorException {
// 升级后的请求对象
Request upgradeRequest = null;
try {
// 验证session确认是否需要升级,如果需要则进行升级操作
upgradeRequest = lzks.checkUpgradeSession(request);
} catch (KeeperException ke) {
if (request.getHdr() != null) {
LOG.debug("Updating header");
request.getHdr().setType(OpCode.error);
request.setTxn(new ErrorTxn(ke.code().intValue()));
}
request.setException(ke);
LOG.info("Error creating upgrade request " + ke.getMessage());
} catch (IOException ie) {
LOG.error("Unexpected error in upgrade", ie);
}
// 如果升级后的请求对象不为空
if (upgradeRequest != null) {
nextProcessor.processRequest(upgradeRequest);
}
nextProcessor.processRequest(request);
}
在上述代码中核心操作流程如下。
- 创建升级请求对象,通过QuorumZooKeeperServer#checkUpgradeSession方法对请求进行检查,检查通过会升级请求。
- 如果在第(1)步的升级过程中发送异常将会把异常相关信息记录到原始请求中。
- 如果升级请求对象不为空将升级后的请求对象交给下一个请求处理器进行处理,反之则将原始请求交给下一个请求处理器进行。
CommitProcessor 分析
本节将对提交处理器CommitProcessor进行分析,该对象用于对一金提交的请求与本地提交的请求进行匹配。CommitProcessor类是多线程的,各个线程之间通讯使用LinkedBlockingQueue数据结构进行通讯。在开始方法分析之前需要了解成员变量,具体信息见表。
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| queuedRequests | LinkedBlockingQueue<Request> | 所有进入CommitProcessor类处理的请求都会先放在该容器中。 |
| committedRequests | LinkedBlockingQueue<Request> | 已经提交的请求 |
| nextPending | AtomicReference<Request> | 正在等待提交的请求 |
| currentlyCommitting | AtomicReference<Request> | 当前正在提交的请求 |
| numRequestsProcessing | AtomicInteger | 已经提交的请求数量 |
| stopped | boolean | 是否暂停工作 |
| workerPool | WorkerService | 工作服务 |
| nextProcessor | RequestProcessor | 下一个请求处理器。在Follower角色中类型是FinalRequestProcessor。在Leader角色中类型是ToBeAppliedRequestProcessor。在Observer角色中类型是FinalRequestProcessor。 |
| matchSyncs | boolean | 是否需要等待leader服务返回。 |
| workerShutdownTimeoutMS | long | work服务超时时间 |
了解成员变量后线面对CommitProcessor类中关于请求的处理方法进行分析,具体代码如下。
@Override
public void processRequest(Request request) {
if (stopped) {
return;
}
if (LOG.isDebugEnabled()) {
LOG.debug("Processing request:: " + request);
}
queuedRequests.add(request);
if (!isWaitingForCommit()) {
wakeup();
}
}
在上述代码主要处理流程如下。
- 判断成员变量stopped是否为真,为真表示停止处理。如果为真则结束处理。
- 将请求对象放入到成员变量queuedRequests中。
- 如果成员变量nextPending数据为空则进行通知操作(唤醒线程)。
在processRequest方法中可以发现它仅仅是将请求对象放入到了queuedRequests变量中,并未做请求的实际处理操作,其真实的请求处理操作是在run方法中,具体代码如下。
@Override
public void run() {
Request request;
try {
// 没有停止的情况下死循环
while (!stopped) {
// 锁
synchronized (this) {
// 需要等待的条件:
// 1. 未停止
// 2.1 queuedRequests集合为空
// 2.2 nextPending 中存在数据
// 2.3 currentlyCommitting 中存在数据
// 3.1 committedRequests为空
// 3.2 numRequestsProcessing数量不为0
while (
!stopped &&
((queuedRequests.isEmpty() || isWaitingForCommit()
|| isProcessingCommit()) &&
(committedRequests.isEmpty()
|| isProcessingRequest()))) {
wait();
}
}
// 处理queuedRequests中的请求
// 死循环条件
// 1. 未停止工作
// 2. nextPending 中存在数据
// 3. currentlyCommitting 中存在数据
// 4. queuedRequests 中获取一个请求对象,该请求对象不为空
while (!stopped && !isWaitingForCommit() &&
!isProcessingCommit() &&
(request = queuedRequests.poll()) != null) {
// 判断是否需要提交
if (needCommit(request)) {
nextPending.set(request);
}
else {
// 发送给下一个请求处理器处理
sendToNextProcessor(request);
}
}
// 处理已提交的请求
processCommitted();
}
} catch (Throwable e) {
handleException(this.getName(), e);
}
LOG.info("CommitProcessor exited loop!");
}
在上述代码中采用死循环的形式进行请求处理,每一个循环阶段执行流程如下。
-
如果满足下面三大类条件将进行线程等待操作。
- 条件1:成员变量stopped为真。
- 条件2由两部分组成。第一部分是queuedRequests集合为空,第二部分是nextPending中存在数据。
- 条件3由两部分组成。第一部分是committedRequests集合为空,第二部分是numRequestsProcessing数量不为0。
-
死循环处理queuedRequests变量中的请求对象,死循环条件有四项需要同时满足
- 成员变量stopped为真。
- 变量nextPending中存在数据。
- 变量currentlyCommitting中存在数据。
- 从变量queuedRequests中获取一个请求对象,该请求对象不为空。
在满足上述四项循环条件的情况下对单个请求处理逻辑:通过needCommit方法判断是否需要提交请求,如果需要则将请求设置到成员变量nextPending中,反之则通过sendToNextProcessor方法交个下一个请求处理器处理。
-
通过processCommitted方法对已提交的请求进行处理。
接下来对上述处理流程中所涉及的一些方法进行分析,首先对needCommit方法进行分析,它的处理流程是根据不同的操作类型做出不同的返回值,具体映射关系见表。
| 请求类型 | 返回值 |
|---|---|
| create、create2、createTTL、createContainer、delete、deleteContainer、setData、reconfig、multi、setACL | true |
| sync | matchSyncs |
| createSession、closeSession | 取反是否是本地session的返回值 |
接下来对sendToNextProcessor方法进行分析,具体处理代码如下。
private void sendToNextProcessor(Request request) {
numRequestsProcessing.incrementAndGet();
workerPool.schedule(new CommitWorkRequest(request), request.sessionId);
}
上述代码主要处理流程如下。
- 计数器累加一。
- 将请求封装为CommitWorkRequest类型后交给工作池进行处理。
从sendToNextProcessor方法中可以发现核心交给workerPool变量进行,该变量的具体类型是WorkerService,其schedule方法代码如下。
public void schedule(WorkRequest workRequest, long id) {
// 判断是否停止处理
if (stopped) {
// 清空请求
workRequest.cleanup();
return;
}
// 转换请求
ScheduledWorkRequest scheduledWorkRequest =
new ScheduledWorkRequest(workRequest);
// 获取任务执行器数量
int size = workers.size();
// 任务执行器数量大于0
if (size > 0) {
try {
int workerNum = ((int) (id % size) + size) % size;
// 取出任务执行器执行
ExecutorService worker = workers.get(workerNum);
worker.execute(scheduledWorkRequest);
} catch (RejectedExecutionException e) {
LOG.warn("ExecutorService rejected execution", e);
workRequest.cleanup();
}
}
else {
scheduledWorkRequest.run();
}
}
在上述代码中核心处理流程如下。
- 判断是否停止处理,如果是则清空请求,并结束处理。
- 分装WorkRequest类型的请求到ScheduledWorkRequest请求中。
- 判断任务执行器数量是否大于0,如果是则需要从任务执行器集合中获取一个任务执行器进行执行,反之则直接执行。
在WorkerService#schedule方法中器核心执行对象是ScheduledWorkRequest,它实现了Runnable接口,具体实现方法如下。
private class ScheduledWorkRequest implements Runnable {
private final WorkRequest workRequest;
ScheduledWorkRequest(WorkRequest workRequest) {
this.workRequest = workRequest;
}
@Override
public void run() {
try {
if (stopped) {
workRequest.cleanup();
return;
}
workRequest.doWork();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
workRequest.cleanup();
}
}
}
在上述代码中可以发现run方法最终会调用WorkRequest#doWork方法来完成请求操作。因此回归到sendToNextProcessor方法上可以发现实际的请求类型是CommitWorkRequest,明确类型后查看doWork函数,具体代码如下。
public void doWork() throws RequestProcessorException {
try {
nextProcessor.processRequest(request);
} finally {
currentlyCommitting.compareAndSet(request, null);
if (numRequestsProcessing.decrementAndGet() == 0) {
if (!queuedRequests.isEmpty() ||
!committedRequests.isEmpty()) {
wakeup();
}
}
}
}
在上 述代码中首先会将请求对象交给下一个请求处理器进行处理,在处理完成后会进行如下操作。
- 将当前请求设置到currentlyCommitting变量中。
- 在numRequestsProcessing数值为0的情况下,如果满足下面两个条件的任意一个则会进行通知操作(唤醒线程)。
- 成员变量queuedRequests不为空。
- 成员变量committedRequests不为空。
最后对processCommitted方法进行分析,具体处理代码如下。
protected void processCommitted() {
// 请求对象
Request request;
// 满足条件执行
// 1. 没有停止工作
// 2. numRequestsProcessing数量为0
// 3. 从committedRequests中取出一个数据不为空
if (!stopped && !isProcessingRequest() &&
(committedRequests.peek() != null)) {
// 1. nextPending中存在数据
// 2. queuedRequests不为空
if (!isWaitingForCommit() && !queuedRequests.isEmpty()) {
return;
}
// 取出请求处理
request = committedRequests.poll();
// 从 nextPending 中取出下一个请求
Request pending = nextPending.get();
// 1. 下一个请求不为空
// 2. 下一个请求与当前请求的sessionId相同
// 3. 下一个请求与当前请求的cxid相同
if (pending != null &&
pending.sessionId == request.sessionId &&
pending.cxid == request.cxid) {
pending.setHdr(request.getHdr());
pending.setTxn(request.getTxn());
pending.zxid = request.zxid;
currentlyCommitting.set(pending);
nextPending.set(null);
sendToNextProcessor(pending);
}
else {
currentlyCommitting.set(request);
sendToNextProcessor(request);
}
}
}
在上述代码中整个处理流程需要首先满足下面三项条件才会进行处理。
- 成员变量stopped为真,表示没有停止工作。
- 成员变量numRequestsProcessing数据值为0。
- 从committedRequests中取出一个数据不为空。
满足上述三项条件后具体处理流程如下。
-
若nextPending中存在数据并且queuedRequests不为空将结束处理。
-
从committedRequests中取出一个请求。
-
从nextPending中获取下一个请求。
-
判断是否满足下面三项条件。
- 下一个请求不为空
- 下一个请求与当前请求的sessionId相同
- 下一个请求与当前请求的cxid相同
如果满足上述三个条件则会将第(2)步中获取的请求信息设置到下一个请求中,设置内容包含hdr、txn和zxid,设置完成后会将下一个请求设置到currentlyCommitting变量中,将nextPending中的数据清空并交给sendToNextProcessor方法进行处理。如果不满足上述三个条件将会把第(2)步中获取的请求对象放入到成员变量currentlyCommitting中,并交给sendToNextProcessor方法进行处理。
ProposalRequestProcessor 分析
本节将对提案请求处理器ProposalRequestProcessor进行分析,在ProposalRequestProcessor类中存在三个成员变量详细信息见表。
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| zks | LeaderZooKeeperServer | Zookeeper的领导者服务。 |
| nextProcessor | RequestProcessor | 下一个请求处理器,具体类型是CommitProcessor。 |
| syncProcessor | SyncRequestProcessor | 同步请求处理器。 |
了解成员变量后下面对processRequest方法进行分析,具体处理代码如下。
public void processRequest(Request request) throws RequestProcessorException {
if (request instanceof LearnerSyncRequest) {
zks.getLeader().processSync((LearnerSyncRequest) request);
} else {
nextProcessor.processRequest(request);
if (request.getHdr() != null) {
try {
// 发送给其他服务
zks.getLeader().propose(request);
} catch (XidRolloverException e) {
throw new RequestProcessorException(e.getMessage(), e);
}
syncProcessor.processRequest(request);
}
}
}
在pendingSyncs方法中处理流程:判断请求是否是LearnerSyncRequest类型,如果是则会交给Leader进行处理,具体处理是发送到Leader服务器进行请求处理。如果不是LearnerSyncRequest类型的请求将交给下一个请求处理器进行请求处理。此外如果在不是LearnerSyncRequest类型的请求下,请求包含hdr属性会将请求发送到其他Zookeeper服务,发送完成以后会调用同步请求处理器进行请求处理。
SyncRequestProcessor 分析
本节将对同步请求处理器SyncRequestProcessor进行分析,在SyncRequestProcessor类中对于请求的处理是将请求对象放入到成员变量queuedRequests中。具体对于请求的处理是在run方法中,代码信息如下。
@Override
public void run() {
try {
// 日志计数器
int logCount = 0;
// 随机快照数量,避免全量快照日志
int randRoll = r.nextInt(snapCount / 2);
while (true) {
Request si = null;
// 从queuedRequests集合中取出请求对象
if (toFlush.isEmpty()) {
si = queuedRequests.take();
} else {
si = queuedRequests.poll();
if (si == null) {
flush(toFlush);
continue;
}
}
// 如果请求对象和死亡请求对象相同则跳出死循环
if (si == requestOfDeath) {
break;
}
if (si != null) {
// 向zk数据库追加当前请求
if (zks.getZKDatabase().append(si)) {
// 日志计数器累加一
logCount++;
// 日志计数器
if (logCount > (snapCount / 2 + randRoll)) {
randRoll = r.nextInt(snapCount / 2);
// roll the log
// 滚动日志
zks.getZKDatabase().rollLog();
// 确认是否需要生成快照
if (snapInProcess != null && snapInProcess.isAlive()) {
LOG.warn("Too busy to snap, skipping");
}
else {
snapInProcess = new ZooKeeperThread("Snapshot Thread") {
public void run() {
try {
// 生成快照
zks.takeSnapshot();
} catch (Exception e) {
LOG.warn("Unexpected exception", e);
}
}
};
// 启动
snapInProcess.start();
}
// 计数器归零
logCount = 0;
}
}
// 等待写入的请求为空
else if (toFlush.isEmpty()) {
if (nextProcessor != null) {
nextProcessor.processRequest(si);
if (nextProcessor instanceof Flushable) {
((Flushable) nextProcessor).flush();
}
}
continue;
}
// 等待写入的请求
toFlush.add(si);
// 超过1000个进行写入操作
if (toFlush.size() > 1000) {
flush(toFlush);
}
}
}
} catch (Throwable t) {
handleException(this.getName(), t);
} finally {
running = false;
}
LOG.info("SyncRequestProcessor exited!");
}
在上述代码中核心处理流程如下。
- 设置日志计数器logCount,初始值为0。
- 随机生成快照数量,随机范围0到快照总量除以2。
- 进入死循环,进行请求输出处理,处理流程如下。
- 创建当前操作请求,使用变量si进行存储。
- 如果成员变量toFlush(等待写出的请求集合)为空则从queuedRequests中获取一个请求将其赋值到变量si中。如果toFlush不为空则从queuedRequests中获取一个请求,并将其赋值到变量si中,若当前请求si为空则进行flush操作同时跳过当前处理。
- 如果变量si和死亡请求相同则跳出死循环结束处理。
- 如果此时si变量不为空将进行如下操作。
- 尝试向zk数据库追加当前请求数据,成功的情况下将日志计数器加1并计算日志计数器是否大于snapCount / 2 + randRoll的运算结果,如果大于则进行日志滚动操作,在滚动操作完成后判断条件:线程snapInProcess不为空并且处于存活状态,如果不满足则会进行经过日志输出,反之则会创建snapInProcess线程进行启动,线程snapInProcess的核心执行逻辑是创建快照。
- 变量toFlush为空的情况下,并且下一个请求处理器不为空,将当前请求si放入进行处理。若下一个请求处理器实现了Flushable接口则还需要在处理完成后调用flush方法。完成上述两项操作后跳过当前循环进行下一个处理。
- 将请求写入到toFlush变量中,并且在toFlush变量中元素数量超过1000时进行flush操作。
在上述处理流程中多次使用flush方法进行操作,关于flush方法的详细代码如下。
private void flush(LinkedList<Request> toFlush)
throws IOException, RequestProcessorException {
if (toFlush.isEmpty()) {
return;
}
zks.getZKDatabase().commit();
while (!toFlush.isEmpty()) {
Request i = toFlush.remove();
if (nextProcessor != null) {
nextProcessor.processRequest(i);
}
}
if (nextProcessor != null && nextProcessor instanceof Flushable) {
((Flushable) nextProcessor).flush();
}
}
在上述代码中核心处理流程如下。
- 判断需要操作的请求集合是否为空,如果为空则结束处理。
- 进行数据提交操作,本质是快照提交(org.apache.zookeeper.server.persistence.FileTxnLog#commit)。
- 循环需要操作的请求集合,直到需要操作的请求集合数量为0结束,单个需要操作的请求处理流程如下。
- 从需要操作的请求集合中获取一个请求。
- 判断下一个请求处理器是否为空,如果不为空则将请求交给下一个请求处理器处理。
- 若下一个请求处理器不为空并且类型是Flushable则进行flush方法调用。
在SyncRequestProcessor的分析过程中反复提到下一个请求处理器,在Zookeeper中SyncRequestProcessor类的下一个请求处理器类型有可能有如下几种情况。
- 在ProposalRequestProcessor类中定义了SyncRequestProcessor的下一个请求处理器类型是AckRequestProcessor。
- 在ObserverZooKeeperServer类中定义了SyncRequestProcessor的下一个请求处理器为null。
- 在FollowerZooKeeperServer类中定义了SyncRequestProcessor的下一个请求处理器类型是SendAckRequestProcessor。
- 在ZooKeeperServer类中定义了SyncRequestProcessor的下一个请求处理器类型是FinalRequestProcessor。
ToBeAppliedRequestProcessor 分析
本节将对ToBeAppliedRequestProcessor类进行分析,在ToBeAppliedRequestProcessor类中核心是完成提案的过滤。在该类中需要注意它所携带的下一个请求处理器的类型必须是FinalRequestProcessor类型的,如果不是该类型将抛出异常(在构造函数中抛出)。
public void processRequest(Request request) throws RequestProcessorException {
next.processRequest(request);
// 如果请求中的hdr(事务头)属性不为空
if (request.getHdr() != null) {
// 从头信息中获取zxid
long zxid = request.getHdr().getZxid();
// 从leader中获取提案集合
Iterator<Proposal> iter = leader.toBeApplied.iterator();
// 遍历提案集合
if (iter.hasNext()) {
Proposal p = iter.next();
// 提案中的请求对象不为空,zxid和当前zxid相同则将当前提案移除并结束处理
if (p.request != null && p.request.zxid == zxid) {
iter.remove();
return;
}
}
LOG.error("Committed request not found on toBeApplied: "
+ request);
}
}
在上述代码中核心处理流程如下。
- 交给下一个请求处理器(FinalRequestProcessor)进行请求处理。
- 如果请求对象的hdr(事务头,头信息)属性不为空则进行如下操作。
- 从头信息中获取zxid。
- 从变量leader中获取提案集合。
- 循环提案集合,若满足提案中的请求对象不为空并且天请求对象中的zxid和前面获取的zxid相同则需要将其从提案集合中移除。
SendAckRequestProcessor 分析
本节将发送ack请求处理器SendAckRequestProcessor进行分析,它的作用是负责发送ack数据包。在该对象中有一个成员变量learner,实际类型是Learner,该类型在实际使用中一般会以Follower或者Observer的形式出现,Learner更多的意义是封装了大量公共函数。在SendAckRequestProcessor类中关于请求处理代码如下。
public void processRequest(Request si) {
// 请求类型不是同步的
if (si.type != OpCode.sync) {
// 创建数据包
QuorumPacket qp = new QuorumPacket(Leader.ACK, si.getHdr().getZxid(), null,
null);
try {
// 写出数据包
learner.writePacket(qp, false);
} catch (IOException e) {
LOG.warn("Closing connection to leader, exception during packet send", e);
try {
if (!learner.sock.isClosed()) {
learner.sock.close();
}
} catch (IOException e1) {
LOG.debug("Ignoring error closing the connection", e1);
}
}
}
}
在上述代码中核心处理流程如下。
- 判断请求类型是否是sync的,如果是则跳过处理。
- 组装ACK数据包。
- 通过成员变量learner将数据包写出,写出的本质是通过OutputArchive接口提供的writeRecord进行写出。
ReadOnlyRequestProcessor 分析
本节将对ReadOnlyRequestProcessor类进行分析,该类服务于ReadOnlyZooKeeperServer类,它是只读服务的首个请求处理器,它的下一个请求处理器是PrepRequestProcessor,具体代码可以在ReadOnlyZooKeeperServer#setupRequestProcessors方法中看到,详细代码如下。
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
RequestProcessor prepProcessor = new PrepRequestProcessor(this, finalProcessor);
((PrepRequestProcessor) prepProcessor).start();
firstProcessor = new ReadOnlyRequestProcessor(this, prepProcessor);
((ReadOnlyRequestProcessor) firstProcessor).start();
}
回到ReadOnlyRequestProcessor类本身查看请求处理方法,具体代码如下。
@Override
public void processRequest(Request request) {
if (!finished) {
queuedRequests.add(request);
}
}
在上述代码中会判断是否已经处理完成,在未处理完成的情况下会将请求放入到需要处理的请求容器queuedRequests中。有关请求的核心处理是依靠线程进行的,具体处理内容在run方法中,详细代码如下。
public void run() {
try {
while (!finished) {
// 从请求列表中获取一个请求
Request request = queuedRequests.take();
// 日志记录
long traceMask = ZooTrace.CLIENT_REQUEST_TRACE_MASK;
if (request.type == OpCode.ping) {
traceMask = ZooTrace.CLIENT_PING_TRACE_MASK;
}
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, traceMask, 'R', request, "");
}
// 如果请求和死亡请求相同则结束处理
if (Request.requestOfDeath == request) {
break;
}
// 过滤请求
switch (request.type) {
case OpCode.sync:
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
// 构造新的头对象
ReplyHeader hdr = new ReplyHeader(request.cxid, zks.getZKDatabase()
.getDataTreeLastProcessedZxid(), Code.NOTREADONLY.intValue());
try {
// 发送响应
request.cnxn.sendResponse(hdr, null, null);
} catch (IOException e) {
LOG.error("IO exception while sending response", e);
}
// 进行下一个处理
continue;
}
// 下一个请求处理器处理器
if (nextProcessor != null) {
nextProcessor.processRequest(request);
}
}
} catch (RequestProcessorException e) {
if (e.getCause() instanceof XidRolloverException) {
LOG.info(e.getCause().getMessage());
}
handleException(this.getName(), e);
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("ReadOnlyRequestProcessor exited loop!");
}
在上述代码中核心处理是在死循环中进行的,循环条件是finished变量为真,其中的单个处理流程如下。
-
从请求列表中获取一个请求。
-
进行日志记录。
-
判断第(1)步中获取的请求是否和死亡请求相同,如果是则结束循环。
-
如果请求类型是 sync 、create 、create2 、createTTL 、createContainer 、delete 、deleteContainer 、setData 、reconfig 、setACL 、multi 、check中的任意一个将构造新的头对象并发送响应。在发送完成后进行下一个请求处理。
-
如果下一个请求处理器不为空将请求交给下一个请求处理器进行处理。
UnimplementedRequestProcessor 分析
本节将对UnimplementedRequestProcessor类进行分析,该类的使用场景是在请求验证不通过的情况下进行使用,入口方法可以查看org.apache.zookeeper.server.ZooKeeperServer#submitRequest。UnimplementedRequestProcessor类中关于请求处理的代码如下。
public void processRequest(Request request) throws RequestProcessorException {
// 创建异常对象
KeeperException ke = new KeeperException.UnimplementedException();
// 向请求中写入异常信息
request.setException(ke);
// 组装响应
ReplyHeader rh = new ReplyHeader(request.cxid, request.zxid,
ke.code().intValue());
try {
// 发送响应
request.cnxn.sendResponse(rh, null, "response");
}
catch (IOException e) {
throw new RequestProcessorException("Can't send the response", e);
}
// 发送关闭session请求
request.cnxn.sendCloseSession();
}
在上述代码中核心处理流程如下。
- 创建异常对象,具体类型为UnimplementedException。
- 向请求对象中写入异常对象。
- 组装响应对象ReplyHeader。
- 发送响应。
- 发送关闭session请求。
在这段代码中核心逻辑是完成异常对象创建,将异常信息返回给客户端并发送关闭session请求。
ObserverRequestProcessor 分析
本节将对ObserverRequestProcessor类进行分析,它的主要职责是将请求转发给Leader服务。在ObserverRequestProcessor类中下一个请求处理器的类型是CommitProcessor,具体可以ObserverZooKeeperServer#setupRequestProcessors方法中看到定义,详细代码如下。
@Override
protected void setupRequestProcessors() {
RequestProcessor finalProcessor = new FinalRequestProcessor(this);
commitProcessor = new CommitProcessor(finalProcessor,
Long.toString(getServerId()), true,
getZooKeeperServerListener());
commitProcessor.start();
firstProcessor = new ObserverRequestProcessor(this, commitProcessor);
((ObserverRequestProcessor) firstProcessor).start();
if (syncRequestProcessorEnabled) {
syncProcessor = new SyncRequestProcessor(this, null);
syncProcessor.start();
}
}
回到ObserverRequestProcessor类本身查看请求处理方法,具体代码如下。
public void processRequest(Request request) {
// 是否已经完成处理
if (!finished) {
// 创建升级请求后的请求对象
Request upgradeRequest = null;
try {
// 通过 ObserverZooKeeperServer 进行请求升级操作
upgradeRequest = zks.checkUpgradeSession(request);
} catch (KeeperException ke) {
if (request.getHdr() != null) {
request.getHdr().setType(OpCode.error);
request.setTxn(new ErrorTxn(ke.code().intValue()));
}
request.setException(ke);
LOG.info("Error creating upgrade request", ke);
} catch (IOException ie) {
LOG.error("Unexpected error in upgrade", ie);
}
// 升级后的请求对象不为空
if (upgradeRequest != null) {
queuedRequests.add(upgradeRequest);
}
queuedRequests.add(request);
}
}
在上述代码中核心处理流程如下。
- 判断是否已经处理完成,如果是则不需要进行任何处理。
- 通过变量zks(实际类型是ObserverZooKeeperServer)进行请求升级操作。
- 如请求升级操作执行失败将进行txn和exception的数据设置。
- 如果请求升级对象不为空将升级的请求对象放入到请求处理容器(queuedRequests)中。
- 将未升级的请求对象放入到请求处理容器中。
关于请求处理容器中的请求处理会在run方法中执行,具体处理代码如下。
@Override
public void run() {
try {
// 是否已处理
while (!finished) {
// 从需要处理的请求中获取一个请求
Request request = queuedRequests.take();
// 日志
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
// 当前处理请求等于死亡请求结束处理
if (request == Request.requestOfDeath) {
break;
}
// 交给下一个请求处理器处理
nextProcessor.processRequest(request);
switch (request.type) {
case OpCode.sync:
// 等待同步请求中加入当前请求
zks.pendingSyncs.add(request);
// 发送数据包
zks.getObserver().request(request);
break;
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
zks.getObserver().request(request);
break;
case OpCode.createSession:
case OpCode.closeSession:
if (!request.isLocalSession()) {
zks.getObserver().request(request);
}
break;
}
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("ObserverRequestProcessor exited loop!");
}
在上述代码中核心是死循环进行处理,循环跳出条件是变量finished为真,单个循环处理流程如下。
-
从需要处理的请求中获取一个请求。
-
判断请求是否是死亡请求,如果是将结束处理。
-
将请求交给下一个请求处理器进行处理。
-
根据不同请求类型做出不同操作。
-
如果请求类型是sync请求将会把请求放入到pendingSyncs集合中并通过Observer发送请求给Leader服务。
-
如果请求类型是create、create2、createTTL、createContainer、delete、deleteContainer、setData、reconfig、setACL、multi、check中的一个将通过Observer发送请求给Leader服务。
-
如果请求类型是createSession或者closeSession将判断请求是否是本地请求,如果不是则将通过Observer发送请求给Leader服务。
-
AckRequestProcessor 分析
本节将对AckRequestProcessor类进行分析,该类用于处理Ack请求,具体处理代码如下。
public void processRequest(Request request) {
QuorumPeer self = leader.self;
if (self != null) {
leader.processAck(self.getId(), request.zxid, null);
}
else {
LOG.error("Null QuorumPeer");
}
}
在上述代码中对于请求的处理很简单,将当前节点id和请求中的zxid交给leader对象进行处理。leader对象的处理代码如下。
synchronized public void processAck(long sid, long zxid, SocketAddress followerAddr) {
if (!allowedToCommit){
return;
}
// 记录日志
if (LOG.isTraceEnabled()) {
LOG.trace("Ack zxid: 0x{}", Long.toHexString(zxid));
for (Proposal p : outstandingProposals.values()) {
long packetZxid = p.packet.getZxid();
LOG.trace("outstanding proposal: 0x{}",
Long.toHexString(packetZxid));
}
LOG.trace("outstanding proposals all");
}
// 跳过处理
if ((zxid & 0xffffffffL) == 0) {
return;
}
// 提案容器数量为0跳过处理
if (outstandingProposals.size() == 0) {
if (LOG.isDebugEnabled()) {
LOG.debug("outstanding is 0");
}
return;
}
// 如果最后提交的zxid大于等于参数zxid将跳过处理
if (lastCommitted >= zxid) {
if (LOG.isDebugEnabled()) {
LOG.debug("proposal has already been committed, pzxid: 0x{} zxid: 0x{}",
Long.toHexString(lastCommitted), Long.toHexString(zxid));
}
return;
}
// 获取提案
Proposal p = outstandingProposals.get(zxid);
// 提案为空跳过处理
if (p == null) {
LOG.warn("Trying to commit future proposal: zxid 0x{} from {}",
Long.toHexString(zxid), followerAddr);
return;
}
// 向提案中添加已经ACK的服务id
p.addAck(sid);
// 尝试提交提案
boolean hasCommitted = tryToCommit(p, zxid, followerAddr);
// 1. 提案提交失败
// 2. 提案中的请求对象不为空并且类型为重载配置
if (hasCommitted && p.request != null && p.request.getHdr().getType() == OpCode.reconfig) {
long curZxid = zxid;
while (allowedToCommit && hasCommitted && p != null) {
curZxid++;
p = outstandingProposals.get(curZxid);
if (p != null) {
hasCommitted = tryToCommit(p, curZxid, null);
}
}
}
}
在上述代码中核心操作是创建提案对象p,并且尝试将提案进行发送。这里发送的提案数据类型有如下几种。
- COMMITANDACTIVATE
- INFORMANDACTIVATE
- COMMIT
- INFORM
FollowerRequestProcessor 分析
本节将对FollowerRequestProcessor类进行分析,FollowerRequestProcessor的主要职责是将请求转发到Leader,关于请求的处理方法代码如下。
public void processRequest(Request request) {
if (!finished) {
Request upgradeRequest = null;
try {
upgradeRequest = zks.checkUpgradeSession(request);
} catch (KeeperException ke) {
if (request.getHdr() != null) {
request.getHdr().setType(OpCode.error);
request.setTxn(new ErrorTxn(ke.code().intValue()));
}
request.setException(ke);
LOG.info("Error creating upgrade request", ke);
} catch (IOException ie) {
LOG.error("Unexpected error in upgrade", ie);
}
if (upgradeRequest != null) {
queuedRequests.add(upgradeRequest);
}
queuedRequests.add(request);
}
}
在上述代码中主要处理流程如下。
- 判断是否已经完成处理,如果是则不在进行处理。
- 将请求进行升级。
- 如果在请求升级过程中发送异常会写入异常相关信息。
- 如果升级后的请求对象不为空将其加入到需要处理的请求集合中。
- 将未升级的请求对象加入到需要处理的请求集合中。
通过请求处理器方法会将请求放入到queuedRequests集合中,对请求的核心处理是在run方法中,具体代码如下。
@Override
public void run() {
try {
while (!finished) {
// 从queuedRequests中获取一个请求
Request request = queuedRequests.take();
if (LOG.isTraceEnabled()) {
ZooTrace.logRequest(LOG, ZooTrace.CLIENT_REQUEST_TRACE_MASK,
'F', request, "");
}
// 请求和死亡请求相同
if (request == Request.requestOfDeath) {
break;
}
// 下一个请求处理器执行
nextProcessor.processRequest(request);
switch (request.type) {
case OpCode.sync:
zks.pendingSyncs.add(request);
zks.getFollower().request(request);
break;
case OpCode.create:
case OpCode.create2:
case OpCode.createTTL:
case OpCode.createContainer:
case OpCode.delete:
case OpCode.deleteContainer:
case OpCode.setData:
case OpCode.reconfig:
case OpCode.setACL:
case OpCode.multi:
case OpCode.check:
zks.getFollower().request(request);
break;
case OpCode.createSession:
case OpCode.closeSession:
if (!request.isLocalSession()) {
zks.getFollower().request(request);
}
break;
}
}
} catch (Exception e) {
handleException(this.getName(), e);
}
LOG.info("FollowerRequestProcessor exited loop!");
}
在上述代码中核心是死循环进行处理,循环跳出条件是变量finished为真,单个循环处理流程如下。
-
从需要处理的请求中获取一个请求。
-
判断请求是否是死亡请求,如果是将结束处理。
-
将请求交给下一个请求处理器进行处理。
-
根据不同请求类型做出不同操作。
-
如果请求类型是sync请求将会把请求放入到pendingSyncs集合中并通过Follower发送请求给leader服务。
-
如果请求类型是create、create2、createTTL、createContainer、delete、deleteContainer、setData、reconfig、setACL、multi、check中的一个将通过ObsFollowerrver发送请求给Leader服务。
-
如果请求类型是createSession或者closeSession将判断请求是否是本地请求,如果不是则将通过Follower发送请求给Leader服务。
-
FinalRequestProcessor 分析
本节将对FinalRequestProcessor类进行分析,FinalRequestProcessor类处于整个请求处理链的末尾是最后一个请求处理器。在FinalRequestProcessor类中对于请求处理的逻辑较多将分段解析,首先是关于事务处理结果的处理代码,具体代码操作如下。
ProcessTxnResult rc = null;
synchronized (zks.outstandingChanges) {
// Zookeeper进行请求处理
rc = zks.processTxn(request);
// 请求中头信息不为空
if (request.getHdr() != null) {
// 获取头信息
TxnHeader hdr = request.getHdr();
// 获取请求中的档案
Record txn = request.getTxn();
// 从头信息中获取zxid
long zxid = hdr.getZxid();
// 1. 没有完成的变化档案集合不为空
// 2. 从没有完成的变化档案集合获取一个档案并将其zxid小于当前zxid
while (!zks.outstandingChanges.isEmpty()
&& zks.outstandingChanges.peek().zxid <= zxid) {
// 没有完成的变化档案集合中移除一个数据
ChangeRecord cr = zks.outstandingChanges.remove();
// 警告日志
if (cr.zxid < zxid) {
LOG.warn("Zxid outstanding " + cr.zxid
+ " is less than current " + zxid);
}
// 从未完成的 变换档案中根据移除的数据地址获取档案,若档案相同则从未完成的变换档案中移除数据
if (zks.outstandingChangesForPath.get(cr.path) == cr) {
zks.outstandingChangesForPath.remove(cr.path);
}
}
}
// 如果是投票数据,添加到提案数据中
if (request.isQuorum()) {
zks.getZKDatabase().addCommittedProposal(request);
}
}
在这段关于事务处理结果的处理代码中主要处理流程如下。
-
通过Zookeeper服务进行请求处理。
-
如果请求头信息为空不做后续处理。
-
从请求中获取头信息、档案信息,从头信息中获取zxid。
-
循环处理未完成的档案集合,具体操作的是变量outstandingChanges和变量outstandingChangesForPath,跳出循环的条件如下。
- 没有完成的变化档案集合(outstandingChanges)不为空
- 从没有完成的变化档案集合获取一个档案并将其zxid小于当前zxid
具体没有完成的变化档案处理流程如下。
- 从outstandingChanges中移除一个档案,将该档案当作需要处理的档案。
- 如果档案操作的档案zxid小于头信息中的zxid将输出警告日志。
- 从outstandingChangesForPath中根据当前操作档案的地址获取档案信息,若获取的档案信息和当前操作档案相同则需要在outstandingChangesForPath中移除数据。
-
如果是投票数据,添加到提案数据中。
在完成 事务处理结果的处理代码后会根据请求类型以及连接对象做出相关处理,具体处理代码如下:
// 1. 请求类型是关闭session
// 2. 连接对象为空
if (request.type == OpCode.closeSession && connClosedByClient(request)) {
// 执行关闭session操作
if (closeSession(zks.serverCnxnFactory, request.sessionId) ||
closeSession(zks.secureServerCnxnFactory, request.sessionId)) {
return;
}
}
// 连接对象为空结束处理
if (request.cnxn == null) {
return;
}
在上述代码中核心处理流程如下。
- 判断是否同时满足以下两个条件,如果满足则会进行session关闭操作。
- 请求类型是关闭session
- 请求对象中的连接对象为空
- 如果请求对象中的连接对象为空结束处理。
在上述处理流程中需要注意:关闭的时候会通过两种连接工厂进行session的关闭操作(两种连接工厂类型都是ServerCnxnFactory),第一种是非安全的连接工厂,第二种是安全的连接工厂。
接下来将对响应处理的前置准备工作进行分析,具体处理代码如下。
// 获取连接对象
ServerCnxn cnxn = request.cnxn;
String lastOp = "NA";
// 请求处理数量减一
zks.decInProcess();
// 状态码
Code err = Code.OK;
// 处理结果
Record rsp = null;
try {
// 1. 头信息不为空
// 2. 头信息类型是error
if (request.getHdr() != null && request.getHdr().getType() == OpCode.error) {
// 请求中的异常不为空将其抛出,反之则新建一个异常抛出
if (request.getException() != null) {
throw request.getException();
} else {
throw KeeperException.create(KeeperException.Code
.get(((ErrorTxn) request.getTxn()).getErr()));
}
}
// 获取请求对象中的异常
KeeperException ke = request.getException();
// 1. 异常不为空
// 2. 请求类型是multi
if (ke != null && request.type != OpCode.multi) {
throw ke;
}
// 省略部分代码
}
在上述代码中主要是针对请求中携带异常的处理,处理流程如下。
- 请求对 象的头信息不为空,并且头信息中的类型是异常则会进行异常抛出操作,抛出操作分为两种。
- 请求对象中的异常对象不为空将其抛出。
- 请求对象中的异常对象为空则新建KeeperException异常抛出。
- 在不满足第(1)执行流程的条件情况下会进行如下操作。
- 从请求对象中获取异常。
- 异常对象不为空并且请求类型是multi的情况下抛出请求对象中的异常。
在处理完成异常信息后会对不同的请求类型做出不同的响应处理操作,首先对ping操作和createSession操作进行分析,具体处理代码如下。
case OpCode.ping: {
// 根据请求创建时间计算服务统计中的一些变量
zks.serverStats().updateLatency(request.createTime);
// 操作标记设置为 PING
lastOp = "PING";
// 更新响应统计
cnxn.updateStatsForResponse(request.cxid, request.zxid, lastOp,
request.createTime, Time.currentElapsedTime());
// 发送响应
cnxn.sendResponse(new ReplyHeader(-2,
zks.getZKDatabase().getDataTreeLastProcessedZxid(), 0), null,
"response");
return;
}
case OpCode.createSession: {
// 根据请求创建时间计算服务统计中的一些变量
zks.serverStats().updateLatency(request.createTime);
// 操作标记设置为 SESS
lastOp = "SESS";
// 更新响应统计
cnxn.updateStatsForResponse(request.cxid, request.zxid, lastOp,
request.createTime, Time.currentElapsedTime());
// 完成会话创建
zks.finishSessionInit(request.cnxn, true);
return;
}
在上述代码中处理流程如下。
-
根据请求创建时间计算服务统计中的变量。
- 变量totalLatency:累计所有请求的延迟时间。
- 变量count:累计总共请求次数。
- 变量minLatency:最小请求延迟。
- 变量maxLatency:最大请求延迟。
-
更新响应统计,统计内容如下。
- 变量lastCxid:最后操作的cxid
- 变量lastZxid:最后操作的zxid
- 变量lastOp:最后的操作类型
- 变量lastResponseTime:最后响应时间
- 变量lastLatency:最后延迟时间
- 变量minLatency:最小延迟时间
- 变量maxLatency:最大延迟时间
- 变量count:累计请求处理次数
- 变量totalLatency:累计延迟时间
-
如果是ping请求将会发送响应,如果是createSession请求将会完成会话创建操作。
其次对getData请求进行分析,具体处理代码如下。
case OpCode.getData: {
lastOp = "GETD";
GetDataRequest getDataRequest = new GetDataRequest();
ByteBufferInputStream.byteBuffer2Record(request.request,
getDataRequest);
// 获取地址对应的数据节点
DataNode n = zks.getZKDatabase().getNode(getDataRequest.getPath());
// 数据节点为空抛出异常
if (n == null) {
throw new KeeperException.NoNodeException();
}
// 验证ACL
PrepRequestProcessor.checkACL(zks, zks.getZKDatabase().aclForNode(n),
ZooDefs.Perms.READ,
request.authInfo);
// 统计信息处理
Stat stat = new Stat();
byte b[] = zks.getZKDatabase().getData(getDataRequest.getPath(), stat,
getDataRequest.getWatch() ? cnxn : null);
rsp = new GetDataResponse(b, stat);
break;
}
在上述代码中核心处理流程如下。
- 设置操作类型。
- 创建GetDataRequest对象,并从请求对象中将数据反序列化到GetDataRequest对象中。
- 从Zookeeper数据库中根据请求对象中的地址获取对应的数据节点。
- 如果数据节点为空将抛出异常。
- 验证ACL。
- 处理统计信息并创建响应对象GetDataResponse。
在根据请求类型做出不同的处理操作时还有其他操作,同质化操作较多故不做全部分析。在响应准备完成后会进行发送响应相关操作,具体代码如下。
// 获取最后的zxid
long lastZxid = zks.getZKDatabase().getDataTreeLastProcessedZxid();
// 创建头信息
ReplyHeader hdr =
new ReplyHeader(request.cxid, lastZxid, err.intValue());
// 根据请求创建时间计算服务统计中的一些变量
zks.serverStats().updateLatency(request.createTime);
// 更新统计信息
cnxn.updateStatsForResponse(request.cxid, lastZxid, lastOp,
request.createTime, Time.currentElapsedTime());
try {
// 发送响应
cnxn.sendResponse(hdr, rsp, "response");
// 如果请求类型是关闭session执行关闭操作
if (request.type == OpCode.closeSession) {
cnxn.sendCloseSession();
}
} catch (IOException e) {
LOG.error("FIXMSG", e);
}
在上述代码中核心处理流程如下。
- 从Zookeeper数据库中获取最后的zxid。
- 创建头信息。
- 更新Zookeeper服务的统计信息。
- 更新连接对象中的统计信息。
- 发送响应。
- 如果请求类型是closeSession发送关闭session信息。
总结
本章对Zookeeper项目中关于请求处理器相关的内容进行分析,在Zookeeper项目中请求处理器以责任链的形式出现,一般第一个请求处理器是PrepRequestProcessor,最后一个请求处理器是FinalRequestProcessor。大部分请求处理器是以线程的形式运行,在请求处理器中提供的processRequest方法中会收集请求对象,然后在线程run方法中取出数据做出具体的请求处理操作。