Zookeeper 数据库
本章开始将对Zookeeper中的数据库概念进行分析,主要围绕ZKDatabase和DataTree类进行分析。
ZKDatabase 分析
本节将对ZKDatabase类进行分析,该类是Zookeeper运行时期最重要的数据存储单元,对于它的分析首先从成员变量进行入手,成员变量数据如下:
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| dataTree | DataTree | 数据树 |
| sessionsWithTimeouts | ConcurrentHashMap<Long, Integer> | session 过期映射表 |
| snapLog | FileTxnSnapLog | 快照日志 |
| minCommittedLog | long | 最小提交日志的zxid |
| maxCommittedLog | long | 最大提交日志的zxid |
| committedLog | LinkedList<Proposal> | 提交日志,专用于存储提案数据 |
| logLock | ReentrantReadWriteLock | 读写锁 |
| commitProposalPlaybackListener | PlayBackListener | 提案提交事件 |
| snapshotSizeFactor | double | 快照大小因子 |
| initialized | boolean | 是否实例化 |
通过成员变量的分析可以了解到ZKDatabase类中存储了以下数据信息。
- Session,会话信息。
- DataTree,节点的数据信息。
- Proposal,提案信息。
在ZKDatabase类中大多数方法是与成员变量进行数据设置获取相关的操作(getter方法和setter方法),对于这些方法不做相关分析。接下来将对加载数据库方法进行分析,负责处理的方法是loadDataBase,具体代码如下。
public long loadDataBase() throws IOException {
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
在上述代码中会通过成员变量snapLog提供的restore方法进行数据加载操作,然后将变量initialized设置为true表示已经实例化。关于restore方法已经在日志文件分析章节中进行讲解本节不做具体分析。了解了loadDataBase方法后需要了解具体的使用场景,使用场景有三个。
- 本类中的截断日志方法,在阶段后需要进行重载操作,方法入口org.apache.zookeeper.server.ZKDatabase#truncateLog。
- 在ZooKeeperServer类中的loadData方法,在这条调用线路中最外层的入口是org.apache.zookeeper.server.ServerCnxnFactory#startup(org.apache.zookeeper.server.ZooKeeperServer, boolean)。
- 在QuorumPeer类中的start方法。
接下来对getProposalsFromTxnLog方法进行分析,该方法用于获取提案信息,该方法拥有两个参数。
- 参数startZxid,表示搜索从哪一个zxid开始。
- 参数sizeLimit,表示检索文件限制大小,该数值用于和快照文件大小比较。
了解参数后下面对方法进行分析,具体处理代码如下。
public Iterator<Proposal> getProposalsFromTxnLog(long startZxid,
long sizeLimit) {
// 如果sizeLimit值为负数则返回空迭代器
if (sizeLimit < 0) {
LOG.debug("Negative size limit - retrieving proposal via txnlog is disabled");
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// 创建事务迭代器
TxnIterator itr = null;
try {
// 通过snapLog读取startZxid开始的事务迭代器
itr = snapLog.readTxnLog(startZxid, false);
// 头 信息不为空并且头信息中的zxid大于参数startZxid,关闭迭代器,返回空迭代器
if ((itr.getHeader() != null)
&& (itr.getHeader().getZxid() > startZxid)) {
LOG.warn("Unable to find proposals from txnlog for zxid: "
+ startZxid);
itr.close();
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// 参数sizeLimit大于0
if (sizeLimit > 0) {
// 获取快照文件大小
long txnSize = itr.getStorageSize();
// 文件大小大于限制大小,关闭迭代器,返回空迭代器
if (txnSize > sizeLimit) {
LOG.info("Txnlog size: " + txnSize + " exceeds sizeLimit: "
+ sizeLimit);
itr.close();
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
}
} catch (IOException e) {
LOG.error("Unable to read txnlog from disk", e);
try {
if (itr != null) {
itr.close();
}
} catch (IOException ioe) {
LOG.warn("Error closing file iterator", ioe);
}
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// 将事务迭代器分装到TxnLogProposalIterator类中返回
return new TxnLogProposalIterator(itr);
}
在上述代码中核心处理流程如下。
- 判断参数sizeLimit是否小于0,如果是将返回空迭代器。
- 通过成员变量snapLog和参数startZxid获取一个事务迭代器(TxnIterator)。
- 判断第(2)步中的事务迭代器满足以下两个条件进行关闭事务迭代器操作并返回空迭代器。
- 事务迭代器中的头信息不为空
- 事务迭代器中的zxid大于当前参数startZxid。
- 如果startZxid大于0进行如下操作。
- 获取事务迭代器中的快照文件大小。
- 如 果快照文件大小大于限制大小(sizeLimit)则关闭事务迭代器操作并返回空迭代器。
- 将事务迭代器分装到TxnLogProposalIterator类中返回。
接下来对截断日志进行分析,处理方法是truncateLog。
public boolean truncateLog(long zxid) throws IOException {
clear();
boolean truncated = snapLog.truncateLog(zxid);
if (!truncated) {
return false;
}
loadDataBase();
return true;
}
在上述代码中处理流程如下。
- 通过clear方法进行数据清理操作。清理项如下。
- 成员变量minCommittedLog,设置为0。
- 成员变量maxCommittedLog,设置为0。
- 成员变量dataTree,重新创建DataTree对象。
- 成员变量sessionsWithTimeouts,容器清空。
- 成员变量committedLog,容器清空。
- 成员变量initialized,设置为false。
- 通过FileTxnSnapLog#truncateLog方法根据zxid进行日志截断。
- 如果截断结果为false则返回false结束处理,如果为true则进行数据重载操作(重载方法loadDataBase)并返回true。
DataTree 分析
本节将对DataTree类进行分析,该类是用于模拟树结构存储的核心类,下面对该类的成员变量进行分析,详细内容如下:
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| rootZookeeper | String | /字符串 |
| procZookeeper | String | /zookeeper字符串 |
| procChildZookeeper | String | zookeeper字符串 |
| quotaZookeeper | String | /zookeeper/quota字符串 |
| quotaChildZookeeper | String | quota字符串 |
| configZookeeper | String | /zookeeper/config字符串 |
| configChildZookeeper | String | config字符串 |
| nodes | ConcurrentHashMap<String, DataNode> | 节点容器,key:节点路径,value:数据节点 |
| dataWatches | WatchManager | 数据监控管理器(观察管理器) |
| childWatches | WatchManager | 子节点监控管理器(观察管理器) |
| pTrie | PathTrie | 前缀匹配树,该类属于工具类,用于对配额(quota)进行管理。 |
| ephemerals | Map<Long, HashSet<String>> | 会话中临时节点集合,key:session id,value:临时节点集合。 |
| containers | Set<String> | 所有节点路径 |
| ttls | Set<String> | 具备过期时间的节点集合 |
| aclCache | ReferenceCountedACLCache | acl 缓存 |
| procDataNode | DataNode | /zookeeper 节点 |
| quotaDataNode | DataNode | /zookeeper/quota 节点 |
| lastProcessedZxid | long | 最后处理的zxid |
| root | DataNode | 根节点 |
了解成员变量后对构造函数进行分析,具体处理代码如下。
public DataTree() {
// 设置空字符串对应root节点
nodes.put("", root);
// 设置/对应root节点
nodes.put(rootZookeeper, root);
// 向root节点添加zookeeper子节点字符串
root.addChild(procChildZookeeper);
// 设置/zookeeper对应procDataNode节点
nodes.put(procZookeeper, procDataNode);
// 向procDataNode节点添加quota子节点字符串
procDataNode.addChild(quotaChildZookeeper);
// 设置/zookeeper/quota对应的quotaDataNode节点
nodes.put(quotaZookeeper, quotaDataNode);
// 添加配置节点
addConfigNode();
}
在上述代码中会完成以下节点的初始化。
- 根节点,节点路径:/。
- zookeeper节点,节点路径:/zookeeper。
- quota节点,节点路径:/zookeeper/quota。
- config节点,节点路径:/zookeeper/config。
在构造函数中主要完成nodes变量的设置,在上述代码中会将成员变量的数据进行初始化然后放入容器,在这段代码中需要注意的是addChild方法,通过addChild方法会在DataNode对象中完成树结构,但是在nodes容器中是平铺的。接下来对构造函数中的addConfigNode方法进行分析,具体处理代码如下。
public void addConfigNode() {
// 获取/zookeeper节点
DataNode zookeeperZnode = nodes.get(procZookeeper);
// 如果/zookeeper节点不为空则向其添加config子节点字符串
if (zookeeperZnode != null) {
zookeeperZnode.addChild(configChildZookeeper);
} else {
assert false : "There's no /zookeeper znode - this should never happen.";
}
// 向nodes容器添加/zookeeper/config路径对应的节点数据
nodes.put(configZookeeper, new DataNode(new byte[0], -1L, new StatPersisted()));
try {
// 设置acl
setACL(configZookeeper, ZooDefs.Ids.READ_ACL_UNSAFE, -1);
} catch (KeeperException.NoNodeException e) {
assert false : "There's no " + configZookeeper +
" znode - this should never happen.";
}
}
在上述代码中处理流程如下。
- 从nodes中获取/zookeeper节点。
- 如果/zookeeper节点不为空则向其添加config子节点字符串,反之则进行断言输出。
- 向nodes容器添加/zookeeper/config路径对应的节点数据。
- 通过setACL方法设置/zookeeper/config节点的权限信息。
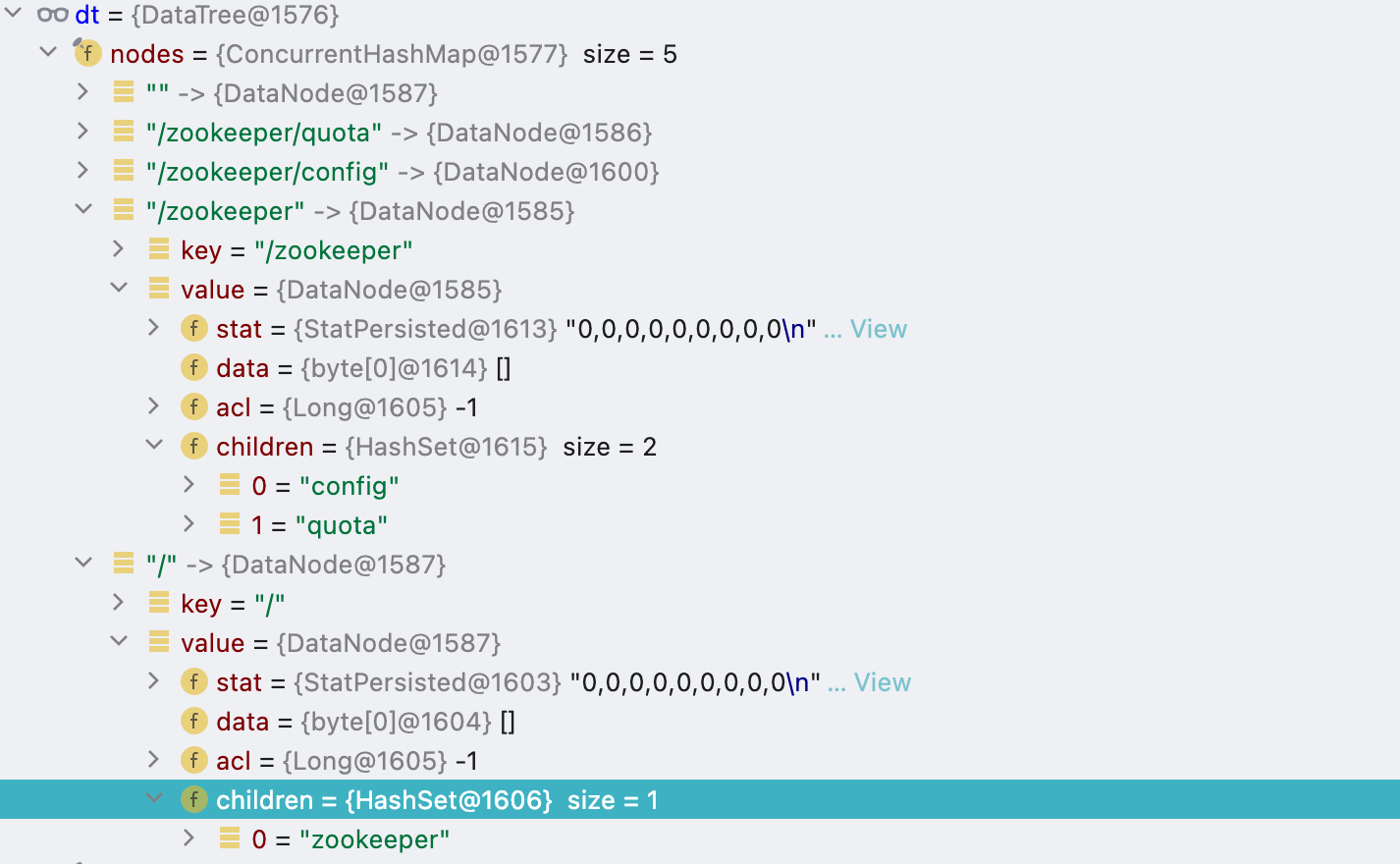
在没有任何数据的情况下,DataTree类初始化后的数据信息如图所示。
ACL操作
本节将对ACL操作相关内容进行分析,在addConfigNode方法中涉及到ACL相关操作中的设置操作,关于ALC还有获取操作下面将对这两种操作进行分析,首先是设置ACL操作,具体处理代码如下。
public Stat setACL(String path, List<ACL> acl, int version)
throws KeeperException.NoNodeException {
// 创建统计对象
Stat stat = new Stat();
// 从nodes容器中根据路径获取节点数据
DataNode n = nodes.get(path);
// 如果节点数据为空抛出异常
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
// 从acl缓存中移除部分数据
aclCache.removeUsage(n.acl);
// 向操作节点设置acl版本号
n.stat.setAversion(version);
// 通过acl缓存转换acl对象将其设置到数据节点的acl变量中
n.acl = aclCache.convertAcls(acl);
// 将数据节点中的统计信息拷贝到新建的统计对象中然后返回
n.copyStat(stat);
return stat;
}
}
在上述代码中核心处理流程如下。
- 创建统计对象(方法返回值)
- 从nodes容器中根据路径获取节点数据,如果节点数据为空则抛出异常。
- 从acl缓存中移除部分数据。
- 向操作节点设置acl版本号。
- 通过acl缓存转换acl对象将其设置到数据节点的acl变量中。
- 将数据节点中的统计信息拷贝到新建的统计对象中然后返回。
在上述方法中需要注意的是返回对象是新建的,并不是将数据本身的统计对象直接返回,其本质是希望与数据本身脱离。接下来对获取ACL数据的getACL方法进行分析,具体处理代码如下。
public List<ACL> getACL(String path, Stat stat)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
return new ArrayList<ACL>(aclCache.convertLong(n.acl));
}
}
在上述代码中核心处理流程如下。
- 从nodes容器中根据路径获取节点数据,如果节点数据为空则抛出异常。
- 将数据节点中的数据拷贝到参数stat对象中。
- 将数据节点中的ACL数据通过ReferenceCountedACLCache#convertLong方法进行转换
节点创建删除操作
本节将对节点的创建操作和删除操作进行分析,主要涉及两个方法createNode和deleteNode,下面先对节点创建方法createNode进行分析,在开始方法分析之前要先对方法参数进行说明,具体信息如下:
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| path | String | 节点路径 |
| data | byte[] | 节点数据 |
| acl | List<ACL> | 节点权限 |
| ephemeralOwner | long | 当前节点的拥有者,拥有者采用会话id(Session id)表示,如果为-1则表示不是一个临时节点,反之则是临时节点。 |
| parentCVersion | int | 父节点的创建版本号 |
| zxid | long | 事务id |
| time | long | 时间 |
| outputStat | Stat | 输出统计信息 |
了解方法参数后下面对方法进行详细说明,完整代码如下。
public void createNode(final String path,
byte data[],
List<ACL> acl,
long ephemeralOwner,
int parentCVersion,
long zxid,
long time,
Stat outputStat)
throws KeeperException.NoNodeException,
KeeperException.NodeExistsException {
// 最后一个斜杠的索引
int lastSlash = path.lastIndexOf('/');
// 确认父节点路径
String parentName = path.substring(0, lastSlash);
// 确认当前操作节点的路径
String childName = path.substring(lastSlash + 1);
// 创建持久化统计对象设置各项数据
StatPersisted stat = new StatPersisted();
stat.setCtime(time);
stat.setMtime(time);
stat.setCzxid(zxid);
stat.setMzxid(zxid);
stat.setPzxid(zxid);
stat.setVersion(0);
stat.setAversion(0);
stat.setEphemeralOwner(ephemeralOwner);
// 获取父节点
DataNode parent = nodes.get(parentName);
// 如果父节点不存在抛出异常
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
// 获取父节点的子节点字符串集合
Set<String> children = parent.getChildren();
// 判断当前子节点是否在子节点字符串集合中
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
// 如果参数父节点的创建版本号为-1,需要重新从父节点中获取并进行累加1操作
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
// 对父节点的统计信息进行重新设置
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
// 转换acl数据
Long longval = aclCache.convertAcls(acl);
// 创建子节点
DataNode child = new DataNode(data, longval, stat);
// 向父节点中添加子节点路径
parent.addChild(childName);
// 将数据放入到节点容器中
nodes.put(path, child);
// 获取临时拥有者的类型
EphemeralType ephemeralType = EphemeralType.get(ephemeralOwner);
// 类型如果是CONTAINER
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
}
// 类型如果是TTL
else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
}
// 如果节点拥有者数据不为0
else if (ephemeralOwner != 0) {
// 从ephemerals容器中获取对应的临时节点路径集合
HashSet<String> list = ephemerals.get(ephemeralOwner);
// 如果临时节点集合为null则创建set集合并加入到容器,反之则将当前操作节点放入到临时节点路径容器中
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
// 如果输出统计对象不为空则进行拷贝操作
if (outputStat != null) {
child.copyStat(outputStat);
}
}
// 如果父节点的路径是以/zookeeper/quota开头
if (parentName.startsWith(quotaZookeeper)) {
// 如果当前路径是zookeeper_limits
if (Quotas.limitNode.equals(childName)) {
// 添加到路径树中
pTrie.addPath(parentName.substring(quotaZookeeper.length()));
}
// 如果当前路径是zookeeper_stats,
if (Quotas.statNode.equals(childName)) {
// 更新quota数据
updateQuotaForPath(parentName
.substring(quotaZookeeper.length()));
}
}
// 最大配额匹配路径
String lastPrefix = getMaxPrefixWithQuota(path);
// 最大配额匹配路径不为空
if (lastPrefix != null) {
// 更新计数器
updateCount(lastPrefix, 1);
// 更新字节数
updateBytes(lastPrefix, data == null ? 0 : data.length);
}
// 触发数据观察事件
dataWatches.triggerWatch(path, Event.EventType.NodeCreated);
// 触发子节点观察事件
childWatches.triggerWatch(parentName.equals("") ? "/" : parentName,
Event.EventType.NodeChildrenChanged);
}
在上述代码中核心处理流程如下。
- 获取最后一个斜杠的索引位置.
- 提取方法参数path数据,从索引位置0开始到最后一个斜杠的索引位置,这部分是当前path数据的父节点路径,使用变量parentName进行存储。
- 提取方法参数path数据,从最后一个斜杠的索引位置开始到最后一个字符,这部分是当前需要操作的子节点路径,使用变量childName进行存储。
- 创建持久化统计对象,并向其设置各项数据。
- 从nodes中获取父节点数据,如果父节点数据不存在则会抛出异常。
- 从父节点中获取子节点字符串集合,判断当前操作的子节点路径(变量childName)是否在集合内,如果在则抛出异常。
- 判断参数parentCVersion是否为-1,如果是则需要从父节点中获取创建版本号将其赋值给参数parentCVersion,赋值完成后需要累加1.
- 重写父节点统计数据中的cversion和pzxid。
- 将acl集合转换为long类型的数据。
- 创建节点对象。
- 向父节点中添加子节点路径(变量childName)。
- 将数据放入到节点容器中。放入的是完整路径(方法参数path)和第(10)步中创建的节点对象。
- 将参数ephemeralOwner转换为EphemeralType,如果此时结果是容器类型(CONTAINER)的节点则需要将该路径数据放入到containers容器中,如果此时结果是过期类型(TTL)的节点则需要将该路径放入到ttls容器中。如果ephemeralOwner数值不为0并且无法通过前两种处理则会进行如下操作。
- 从ephemerals容器中获取ephemeralOwner对应的临时节点路径集合。
- 如果临时节点路径集合为null,则需要创建容器并向ephemerals容器中加入ephemeralOwner和临时节点路径的映射关系。如果临时节点路径集合不为null,则向节点路径集合中加入当前操作的全路径(参数path)。
- 如果输出统计对象不为空则需要将子节点(第10步中中的节点对象)中的统计数据拷贝到统计输出对象中。
- 如果父节点的路径是以/zookeeper/quota开头则需要进行如下操作。
- 如果子节点路径(变量childName)是zookeeper_limits,则需要将父路径进行字符串拆分,拆分保留/zookeeper/quota以后的文本信息将其加入到pTrie对象中。如果需要创建zookeeper_limits结尾的路径,一般路径是以/zookeeper/quota/xxx(可以有多级目录)/zookeeper_limits 形式存在
- 如果子节点路径(变量childName)是zookeeper_stats,则需要通过updateQuotaForPath方法更新quota数据信息。如果需要创建zookeeper_stats结尾的路径,一般路径是以/zookeeper/quota/xxx(可以有多级目录)/zookeeper_stats 形式存在
- 通过getMaxPrefixWithQuota方法提取参数path的最大配额匹配路径,如果最大配额匹配路径不为空则需要进行如下操作。
- 更新计数器。
- 更新字节数。
- 触发两个观察事件。
- 数据观察事件。
- 子节点观察事件。
在创建节点的时候还会使用到一些方法,下面对这些方法进行分析,首先是updateQuotaForPath方法,具体处理代码如下。
private void updateQuotaForPath(String path) {
// 创建计数器
Counts c = new Counts();
// 获取path的计数器信息
getCounts(path, c);
// 创建StatsTrack对象
StatsTrack strack = new StatsTrack();
// 设置字节数
strack.setBytes(c.bytes);
// 设置总量
strack.setCount(c.count);
// 组合 zookeeper_stats 地址
String statPath = Quotas.quotaZookeeper + path + "/" + Quotas.statNode;
// 获取 zookeeper_stats 节点
DataNode node = getNode(statPath);
// 如果节点为空不做处理
if (node == null) {
LOG.warn("Missing quota stat node " + statPath);
return;
}
synchronized (node) {
// 将数据进行覆写
node.data = strack.toString().getBytes();
}
}
在上述代码中核心处理流程如下。
- 创建计数器对象(Counts)。
- 获取path对应的计数器信息,将数据写入到第(1)步创建的对象中.
- 创建StatsTrack对象,将计数器对象中的数据拷贝到StatsTrack对象中。
- 组合zookeeper_stats地址,组合规则:/zookeeper/quota+操作地址+/zookeeper_stats
- 从nodes容器中根据第(4)步得到的地址获取数据节点,数据节点为空则结束处理,反之则需要对数据节点中的data属性进行重写,重写内容是第(3)步中对象的toString方法的字节表示。
在updateQuotaForPath方法中需要通过getCounts方法得到计数器数据,具体计算过程代码如下。
private void getCounts(String path, Counts counts) {
// 根据路径获取节点对象
DataNode node = getNode(path);
// 节点对象为空不做操作
if (node == null) {
return;
}
String[] children = null;
int len = 0;
synchronized (node) {
// 获取当前节点对象的子节点路径
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
// 计算字节长度
len = (node.data == null ? 0 : node.data.length);
}
// 累加数据
counts.count += 1;
counts.bytes += len;
// 循环子节点重复处理路径
for (String child : children) {
getCounts(path + "/" + child, counts);
}
}
在上述代码中核心处理流程如下。
- 从nodes容器中根据路径获取数据节点对象,如果数据节点对象为空则不做处理。
- 从第(1)步中获取子节点路径集合并且计算当前数据节点中数据的长度(字节长度)。
- 将方法参数counts中的count字段进行累加1操作,表示节点数量增加一个。将方法参数counts中的bytes累加第(2)步中的数据长度。
- 循环处理子节点路径集合进行第(1)~第(3)步的处理。
接下来对updateCount方法进行分析,该方法用于更新count数据,具体处理代码如下。
public void updateCount(String lastPrefix, int diff) {
// 组装路径,/zookeeper/quota + lastPrefix + /zookeeper_stats
String statNode = Quotas.statPath(lastPrefix);
// 获取数据节点
DataNode node = nodes.get(statNode);
StatsTrack updatedStat = null;
// 数据节点为空
if (node == null) {
LOG.error("Missing count node for stat " + statNode);
return;
}
synchronized (node) {
// 将数据进行覆写
updatedStat = new StatsTrack(new String(node.data));
// 设置新的count信息
updatedStat.setCount(updatedStat.getCount() + diff);
// 覆盖数据节点的data数据
node.data = updatedStat.toString().getBytes();
}
// 组装路径 /zookeeper/quota + lastPrefix + /zookeeper_limits
String quotaNode = Quotas.quotaPath(lastPrefix);
// 获取数据节点
node = nodes.get(quotaNode);
StatsTrack thisStats = null;
if (node == null) {
LOG.error("Missing quota node for count " + quotaNode);
return;
}
synchronized (node) {
// 从数据节点中获取data信息将其装换为StatsTrack对象
thisStats = new StatsTrack(new String(node.data));
}
// 警告日志
if (thisStats.getCount() > -1 && (thisStats.getCount() < updatedStat.getCount())) {
LOG
.warn("Quota exceeded: " + lastPrefix + " count="
+ updatedStat.getCount() + " limit="
+ thisStats.getCount());
}
}
在上述代码中核心处理流程如下。
- 组装zookeeper_stats节点的完整路径,组装规则:/zookeeper/quota + lastPrefix + /zookeeper_stats
- 从nodes容器中获取zookeeper_stats节点对应的数据节点,如果数据节点为空则结束处理。
- 从zookeeper_stats节点的数据节点中获取data信息将其装换为StatsTrack对象,向其中设置count数据,设置内容是历史count数据加参数diff(在创建节点中diff数据值表示为1),重新设置count信息后会将其进行toString并转换为字节数组赋值给zookeeper_stats节点对应的数据节点。
- 组装zookeeper_limits节点的完整路径,组装规则:/zookeeper/quota + lastPrefix + /zookeeper_limits。
- 从nodes容器中获取zookeeper_limits节点对应的数据节点,如果数据节点为空则结束处理。
- 从zookeeper_limits节点的数据节点中获取data信息将其转换为StatsTrack对象。
- 如果满足下面两个条件将输出警告日志。
- zookeeper_limits节点的StatsTrack对象计数器大于-1。
- zookeeper_limits节点的StatsTrack对象计数器小于zookeeper_stats节点的StatsTrack对象计数器。
最后对updateBytes方法进行分析,该方法用于更新bytes数据,具体处理代码如下。
public void updateBytes(String lastPrefix, long diff) {
// 组装路径,/zookeeper/quota + lastPrefix + /zookeeper_stats
String statNode = Quotas.statPath(lastPrefix);
DataNode node = nodes.get(statNode);
if (node == null) {
LOG.error("Missing stat node for bytes " + statNode);
return;
}
StatsTrack updatedStat = null;
synchronized (node) {
updatedStat = new StatsTrack(new String(node.data));
updatedStat.setBytes(updatedStat.getBytes() + diff);
node.data = updatedStat.toString().getBytes();
}
// 组装路径 /zookeeper/quota + lastPrefix + /zookeeper_limits
String quotaNode = Quotas.quotaPath(lastPrefix);
node = nodes.get(quotaNode);
if (node == null) {
LOG.error("Missing quota node for bytes " + quotaNode);
return;
}
StatsTrack thisStats = null;
synchronized (node) {
thisStats = new StatsTrack(new String(node.data));
}
if (thisStats.getBytes() > -1 && (thisStats.getBytes() < updatedStat.getBytes())) {
LOG
.warn("Quota exceeded: " + lastPrefix + " bytes="
+ updatedStat.getBytes() + " limit="
+ thisStats.getBytes());
}
}
在上述代码中核心处理流程如下。
- 组装zookeeper_stats节点的完整路径,组装规则:/zookeeper/quota + lastPrefix + /zookeeper_stats
- 从nodes容器中获取zookeeper_stats节点对应的数据节点,如果数据节点为空则结束处理。
- 从zookeeper_stats节点的数据节点中获取data信息将其装换为StatsTrack对象,向其中设置bytes数据,设置内容是历史bytes数据加参数diff(在创建节点中diff数据值表示为数据本身的长度),重新设置bytes信息后会将其进行toString并转换为字节数组赋值给zookeeper_stats节点对应的数据节点。
- 组装zookeeper_limits节点的完整路径,组装规则:/zookeeper/quota + lastPrefix + /zookeeper_limits。
- 从nodes容器中获取zookeeper_limits节点对应的数据节点,如果数据节点为空则结束处理。
- 从zookeeper_limits节点的数据节点中获取data信息将其转换为StatsTrack对象。
- 如果满足下面两个条件将输出警告日志。
- zookeeper_limits节点的StatsTrack对象中的bytes数据大于-1。
- zookeeper_limits节点的StatsTrack对象中的bytes数据小于zookeeper_stats节点的StatsTrack对象中的bytes数据。
方法updateCount、方法updateBytes和方法updateQuotaForPath着重用于对配额相关信息进行操作。至此对于创建节点相关的代码已经分析完毕,下面将开始对删除节点的deleteNode方法进行分析,具体处理代码如下。
public void deleteNode(String path, long zxid)
throws KeeperException.NoNodeException {
// 最后一个斜杠的索引
int lastSlash = path.lastIndexOf('/');
// 确认父节点路径
String parentName = path.substring(0, lastSlash);
// 确认当前操作节点的路径
String childName = path.substring(lastSlash + 1);
// 获取父节点路径对应的数据节点
DataNode parent = nodes.get(parentName);
// 父节点不存在
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
// 父节点的child属性中移除当前操作节点路径
parent.removeChild(childName);
// 如果zxid大于父节点中的pzxid需要重写父节点中的pzxid
if (zxid > parent.stat.getPzxid()) {
parent.stat.setPzxid(zxid);
}
}
// 获取当前操作路径的数据节点
DataNode node = nodes.get(path);
// 数据节点为空
if (node == null) {
throw new KeeperException.NoNodeException();
}
// 从nodes容器中移除当前操作路径对应的数据
nodes.remove(path);
synchronized (node) {
// 删除acl缓存中相关数据
aclCache.removeUsage(node.acl);
}
synchronized (parent) {
// 获取拥有者
long eowner = node.stat.getEphemeralOwner();
// 将拥有者转换为EphemeralType
EphemeralType ephemeralType = EphemeralType.get(eowner);
// 如果是CONTAINER
if (ephemeralType == EphemeralType.CONTAINER) {
containers.remove(path);
}
// 如果是TTL
else if (ephemeralType == EphemeralType.TTL) {
ttls.remove(path);
}
// 如果拥有者表示为非0
else if (eowner != 0) {
// 从ephemerals容器中根据拥有者信息获取路基信息将当前路径从中移除
HashSet<String> nodes = ephemerals.get(eowner);
if (nodes != null) {
synchronized (nodes) {
nodes.remove(path);
}
}
}
}
// 如果父节点路径是以/zookeeper开头并且子节点路径是zookeeper_limits
if (parentName.startsWith(procZookeeper) && Quotas.limitNode.equals(childName)) {
// 从pTrie容器中删除
pTrie.deletePath(parentName.substring(quotaZookeeper.length()));
}
// also check to update the quotas for this node
// 最大配额匹配路径
String lastPrefix = getMaxPrefixWithQuota(path);
// 最大配额匹配路径不为空
if (lastPrefix != null) {
// 更新count和bytes
updateCount(lastPrefix, -1);
int bytes = 0;
synchronized (node) {
bytes = (node.data == null ? 0 : -(node.data.length));
}
updateBytes(lastPrefix, bytes);
}
if (LOG.isTraceEnabled()) {
ZooTrace.logTraceMessage(LOG, ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"dataWatches.triggerWatch " + path);
ZooTrace.logTraceMessage(LOG, ZooTrace.EVENT_DELIVERY_TRACE_MASK,
"childWatches.triggerWatch " + parentName);
}
// 触发观察者
Set<Watcher> processed = dataWatches.triggerWatch(path,
EventType.NodeDeleted);
childWatches.triggerWatch(path, EventType.NodeDeleted, processed);
childWatches.triggerWatch("".equals(parentName) ? "/" : parentName,
EventType.NodeChildrenChanged);
}
在上述代码中核心处理流程如下。
-
获取最后一个斜杠的索引位置.
-
提取方法参数path数据,从索引位置0开始到最后一个斜杠的索引位置,这部分是当前path数据的父节点路径,使用变量parentName进行存储。
-
提取方法参数path数据,从最后一个斜杠的索引位置开始到最后一个字符,这部分是当前需要操作的子节点路径,使用变量childName进行存储。
-
从nodes中获取父节点数据,如果父节点数据不存在则会抛出异常。
-
从父节点中获取子节点字符串集合,将当前操作的子节点路径(变量childName)从集合内移除。
-
当方法参数zxid大于父节点统计对象中的pzxid,则需要将方法参数zxid赋值到父节点统计对象中的pzxid。
-
从nodes容器中根据方法参数path获取需要删除的数据节点,如果数据节点为空则抛出异常。
-
从nodes容器中移除当前操作路径(参数path)对应的数据。
-
删除acl缓存中相关数据。
-
获取需要删除节点的拥有者标识,将拥有者标识转换为EphemeralType类型,对EphemeralType类型做出不同操作。
- 如果转换结果是CONTAINER,则需要从containers容器中中删除当前操作路径相关数据。
- 如果转换结果是TTL,则需要从ttls容器中删除当前操作路径相关数据。
- 如果拥有者标识不属于CONTAINER类型或者TTL类型,但是拥有者标识为非0则需要在ephemerals容器中根据拥有者信息获取路基信息将当前路径从中移除。
-
如果父节点路径是以/zookeeper开头并且子节点路径是zookeeper_limits则需要从pTrie容器中删除数据。
-
通过getMaxPrefixWithQuota方法获取最大配额匹配路径,如果该路径不为空则需要进行如下操作,
- 更新计数器。
- 更新字节数。
-
触发观察者。
设置数据与获取数据操作
本节将对节点的设置数据与获取数据操作操作进行分析,主要涉及两个方法setData和getData,下面先对setData方法进行分析,具体处理代码如下。
public Stat setData(String path, byte data[], int version, long zxid,
long time) throws KeeperException.NoNodeException {
// 创建统计对象
Stat s = new Stat();
// 获取数据节点
DataNode n = nodes.get(path);
// 数据节点为空
if (n == null) {
throw new KeeperException.NoNodeException();
}
byte lastdata[] = null;
synchronized (n) {
// 从数据节点中获取历史数据
lastdata = n.data;
// 赋值新数据
n.data = data;
n.stat.setMtime(time);
n.stat.setMzxid(zxid);
n.stat.setVersion(version);
// 拷贝统计对象
n.copyStat(s);
}
// 最大配额匹配路径
String lastPrefix = getMaxPrefixWithQuota(path);
// 最大配额匹配路径不为空
if (lastPrefix != null) {
// 更新bytes
this.updateBytes(lastPrefix, (data == null ? 0 : data.length)
- (lastdata == null ? 0 : lastdata.length));
}
// 触发观察者
dataWatches.triggerWatch(path, EventType.NodeDataChanged);
return s;
}
在上述代码中核心处理流程如下。
- 创建统计对象,用于存储返回值。
- 根据参数path获取数据节点,如果数据节点为空抛出异常。
- 更新数据节点中的数据,更新数据如下。
- 数据信息data。
- 统计信息mtime、mzxid和version
- 更新完成节点中的数据信息后将数据拷贝到第(1)步中的统计对象。
- 从参数path中获取最大配额匹配路径,如果最大配额匹配路径不为空,则更新bytes数据。
- 触发观察者。
- 返回统计对象。
接下来对获取数据操作进行分析,具体处理代码如下。
public byte[] getData(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
if (watcher != null) {
dataWatches.addWatch(path, watcher);
}
return n.data;
}
}
在上述代码中核心处理流程如下。
- 根据参数path获取数据节点,如果数据节点为空抛出异常。
- 将数据节点中的统计数据拷贝到参数stat中。
- 如果参数观察者不为空的情况下需要将观察者加入到数据观察者容器中。
- 返回第(1)步数据节点中的数据信息。
获取子节点操作
本节将对获取节点操作进行分析,具体及处理方法是getChildren,详细代码如下。
public List<String> getChildren(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
if (stat != null) {
n.copyStat(stat);
}
List<String> children = new ArrayList<String>(n.getChildren());
if (watcher != null) {
childWatches.addWatch(path, watcher);
}
return children;
}
}
在上述代码中核心处理流程如下。
- 根据参数path获取数据节点,如果数据节点为空抛出异常。
- 如果方法参数stat不为空,则需要将第(1)步数据节点中的stat对象拷贝到参数stat中。
- 从第(1)步的数据节点中获取子节点路径。
- 如果参数观察者不为空的情况下需要将观察者加入到数据观察者容器中。
- 返回第(3)步中的数据。
删除session操作
本节将对删除session操作进行分析,处理方法是killSession具体代码如下。
void killSession(long session, long zxid) {
// 从ephemerals容器中获取对应的临时节点路径
HashSet<String> list = ephemerals.remove(session);
// 如果临时节点路径不为空
if (list != null) {
// 循环删除节点
for (String path : list) {
try {
deleteNode(path, zxid);
if (LOG.isDebugEnabled()) {
LOG
.debug("Deleting ephemeral node " + path
+ " for session 0x"
+ Long.toHexString(session));
}
} catch (NoNodeException e) {
LOG.warn("Ignoring NoNodeException for path " + path
+ " while removing ephemeral for dead session 0x"
+ Long.toHexString(session));
}
}
}
}
在上述代码中核心处理流程:从ephemerals容器中获取对应的临时结点路径集合,如果临时节点集合不为空则需要调用deleteNode方法将临时节点路径对应的数据删除。
序列化节点与反序列化节点操作
本节将对序列化节点与反序列化节点操作进行分析,涉及到serializeNode方法和deserialize方法,先对serializeNode方法进行分析,具体处理代码如下。
void serializeNode(OutputArchive oa, StringBuilder path) throws IOException {
// 获取路径字符串表示
String pathString = path.toString();
// 获取数据节点
DataNode node = getNode(pathString);
// 数据节点为空
if (node == null) {
return;
}
String children[] = null;
DataNode nodeCopy;
synchronized (node) {
// 创建统计对象
StatPersisted statCopy = new StatPersisted();
// 将数据节点中的统计信息拷贝到统计对象中
copyStatPersisted(node.stat, statCopy);
// 根据原有数据节点创建一个拷贝的数据节点
nodeCopy = new DataNode(node.data, node.acl, statCopy);
// 获取数据节点的子节点集合
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
}
// 序列化数据 path 和 node
serializeNodeData(oa, pathString, nodeCopy);
// 路径地址后加上斜杠
path.append('/');
// 地址长度
int off = path.length();
// 循环子节点集合序列化子节点数据
for (String child : children) {
path.delete(off, Integer.MAX_VALUE);
path.append(child);
serializeNode(oa, path);
}
}
在上述代码中核心处理流程如下。
- 根据路径获取数据节点,如果数据节点不存在则跳过处理。
- 创建统计对象,将数据节点中的统计信息拷贝到统计对象中。
- 创建数据节点的拷贝对象。
- 获取数据节点对象中的子节点路径集合。
- 通过serializeNodeData方法序列化path和node数据到oa变量中。
- 循环子节点路径集合对其进行序列化操作。
接下来对反序列化方法进行分析,该方法是serializeNode方法的逆向过程,具体处理代码如下。
public void deserialize(InputArchive ia, String tag) throws IOException {
// 将ia中的数据反序列化到acl缓存中
aclCache.deserialize(ia);
// 将nodes和pTrie清空
nodes.clear();
pTrie.clear();
// 从ia中获取path数据
String path = ia.readString("path");
// 循环处理节点,当节点为/时结束处理
while (!"/".equals(path)) {
// 创建数据节点对象
DataNode node = new DataNode();
// 从ia容器中获取node数据
ia.readRecord(node, "node");
// 向nodes容器添加数据
nodes.put(path, node);
// 处理acl缓存
synchronized (node) {
aclCache.addUsage(node.acl);
}
// 获取最后一个斜杠的索引
int lastSlash = path.lastIndexOf('/');
// 如果不存在则将当前节点设置为root节点
if (lastSlash == -1) {
root = node;
}
else {
// 提取父节点路径
String parentPath = path.substring(0, lastSlash);
// 从nodes容器中获取父节点
DataNode parent = nodes.get(parentPath);
// 父节点为空
if (parent == null) {
throw new IOException("Invalid Datatree, unable to find " +
"parent " + parentPath + " of path " + path);
}
// 添加子节点路径
parent.addChild(path.substring(lastSlash + 1));
// 获取拥有者标识
long eowner = node.stat.getEphemeralOwner();
// 拥有者类型
EphemeralType ephemeralType = EphemeralType.get(eowner);
// CONTAINER类型
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
}
// TTL类型
else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
}
// 拥有者非0
else if (eowner != 0) {
// 获取ephemerals容器中对应的路径集合
HashSet<String> list = ephemerals.get(eowner);
// 路径集合为空创建新的路径容器加入到ephemerals容器中
if (list == null) {
list = new HashSet<String>();
ephemerals.put(eowner, list);
}
// 向路径集合中放入到路径中
list.add(path);
}
}
// 覆盖path
path = ia.readString("path");
}
// 向nodes容器添加根数据
nodes.put("/", root);
// 设置配额节点
setupQuota();
// 清除acl中的未使用数据
aclCache.purgeUnused();
}
在上述代码中核心操作如下。
- 从输入档案(变量ia)中获取路径数据。
- 循环路径数据,直到路径数据为斜杠("/")时结束处理。
- 向nodes容器添加根数据。
- 通过setupQuota方法对配额节点进行初始化。
- 清除acl缓存中未使用的数据。
在上述处理流程中第(2)步的循环处理逻辑如下。
-
创建数据节点对象,从输入档案中读取node信息将信息放入到数据节点中。
-
向nodes容器添加数据。
-
将数据节点中的acl数据放入到acl缓存中。
-
获取当前操作路径中的最后一个斜杠的索引位置。如果索引位置是-1,则将数据节点对象设置为root节点。如果索引位置不是-1则进行如下操作。
- 从路径地址中获取父节点路径,提取范围:0~最后一个斜杠的索引位置。
- 从 nodes容器中获取父节点路径对应的数据节点,若父节点对应的数据节点为空则抛出异常。
- 向父数据节点添加子节点路径。
- 获取当前操作数据节点的拥有者标识,如果拥有者标识为CONTAINER类型,则需要向容器containers添加路径数据,如果拥有者标识为TTL类型,则需要向容器ttls添加路径数据,如果拥有者标识不属于CONTAINER类型或者TTL类型,但是拥有者标识为非0则需要在ephemerals容器中添加相关数据。
-
从输入档案中读取路径信息覆盖path变量。
配额节点操作
本节将 对配额节点操作相关方法进行分析,具体处理方法是setupQuota,详细代码如下。
private void setupQuota() {
String quotaPath = Quotas.quotaZookeeper;
DataNode node = getNode(quotaPath);
if (node == null) {
return;
}
traverseNode(quotaPath);
}
在上述代码中核心处理流程: 从nodes容器中获取/zookeeper/quota路径对应的数据节点,如果数据节点不存在则不做处理,反之则通过traverseNode方法进行处理。在traverseNode方法中会操作/zookeeper/quota路径下的数据,具体处理代码如下。
private void traverseNode(String path) {
// 获取数据节点
DataNode node = getNode(path);
// 获取子节点路径集合
String children[] = null;
synchronized (node) {
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
}
// 子节点路径集合长度为0的情况下
if (children.length == 0) {
// 组合结尾路径 /zookeeper_limits
String endString = "/" + Quotas.limitNode;
// 判断路径是否是/zookeeper_limits结尾
if (path.endsWith(endString)) {
// 得到 /zookeeper/quota/和/zookeeper_limits之间的路径
String realPath = path.substring(Quotas.quotaZookeeper
.length(), path.indexOf(endString));
// 更新配额数据
updateQuotaForPath(realPath);
// 添加路径
this.pTrie.addPath(realPath);
}
return;
}
// 循环子路径处理
for (String child : children) {
traverseNode(path + "/" + child);
}
}
在上述代码中核心处理流程如下。
- 根据路径地址获取数据节点,第一次操作时所获取的路径是/zookeeper/quota。
- 获取数据节点的子节点路径集合。
- 如果子节点路径集合长度为0的情况下进行如下操作。
- 得到路径/zookeeper/quota/和/zookeeper_limits路径之间的路径,该路径称之为真实路径。
- 通过updateQuotaForPath方法更新真实路径相关的配额信息。
- 将真实路径放入到pTrie变量中。
- 循环第(2)步的子路径信息重复第(1)~(4)步操作。
观察者相关操作
本节将对观察者(Watcher)相关操作进行分析,涉及到的操作有如下三个。
- 方法setWatches用于设置观察者。
- 方法removeWatch用于移除观察者。
- 方法containsWatcher用于判断是否存在观察者。
在Zookeeper项目中对于观察者观察的数据信息包含三类分别是。
- 观察节点数据信息,对应的存储容器名称通常是dataWatches
- 观察节点是否存在,对应的存储容器名称通常是existWatches
- 观察子节点信息,对应的存储容器名称名称通常childWatches
下面对setWatches方法进行分析,具体处理代码如下。
public void setWatches(long relativeZxid, List<String> dataWatches,
List<String> existWatches, List<String> childWatches,
Watcher watcher) {
// 循环数据观察路径
for (String path : dataWatches) {
DataNode node = getNode(path);
WatchedEvent e = null;
if (node == null) {
watcher.process(new WatchedEvent(EventType.NodeDeleted,
KeeperState.SyncConnected, path));
}
else if (node.stat.getMzxid() > relativeZxid) {
watcher.process(new WatchedEvent(EventType.NodeDataChanged,
KeeperState.SyncConnected, path));
}
else {
this.dataWatches.addWatch(path, watcher);
}
}
// 循环观察节点是否存在路径
for (String path : existWatches) {
DataNode node = getNode(path);
if (node != null) {
watcher.process(new WatchedEvent(EventType.NodeCreated,
KeeperState.SyncConnected, path));
}
else {
this.dataWatches.addWatch(path, watcher);
}
}
// 循环观察子节点路径
for (String path : childWatches) {
DataNode node = getNode(path);
if (node == null) {
watcher.process(new WatchedEvent(EventType.NodeDeleted,
KeeperState.SyncConnected, path));
}
else if (node.stat.getPzxid() > relativeZxid) {
watcher.process(new WatchedEvent(EventType.NodeChildrenChanged,
KeeperState.SyncConnected, path));
}
else {
this.childWatches.addWatch(path, watcher);
}
}
}
在上述代码中主要处理流程如下。
- 循环处理dataWatches数据,单个数据处理流程如下。
- 从nodes容器中根据当前操作路径获取数据节点。
- 如果数据节点为空,则交给参数watcher进行事件处理。
- 如果数据节点中的mzxid大于参数zxid,则交给参数watcher进行事件处理。
- 不满足前两种情况将数据加入到dataWatches容器中。
- 循环处理existWatches数据,单个数据处理流程如下。
- 从nodes容器中根据当前操作路径获取数据节点。
- 如果数据节点为空,则交给参数watcher进行事件处理。
- 如果数据节点不为空,将数据加入到dataWatches容器中。
- 循环处理childWatches数据,单个数据处理流程如下。
- 从nodes容器中根据当前操作路径获取数据节点。
- 如果数据节点为空,则交给参数watcher进行事件处理。
- 如果数据节点中的mzxid大于参数zxid,则交给参数watcher进行事件处理。
- 不满足前两种情况将数据加入到childWatches容器中。 在上述处理流程中核心是两类操作。
- 立即触发观察者进行处理。
- 将数据放入观察者容器中,后续在进行处理。
接下来对removeWatch方法进行分析,具体处理代码如下。
public boolean removeWatch(String path, WatcherType type, Watcher watcher) {
boolean removed = false;
switch (type) {
case Children:
removed = this.childWatches.removeWatcher(path, watcher);
break;
case Data:
removed = this.dataWatches.removeWatcher(path, watcher);
break;
case Any:
if (this.childWatches.removeWatcher(path, watcher)) {
removed = true;
}
if (this.dataWatches.removeWatcher(path, watcher)) {
removed = true;
}
break;
}
return removed;
}
在上述代码中核心操作是根据不同的观察类型进行数据删除操作,具体删除分类如下。
- 当类型是Children将在childWatches容器中删除相关数据。
- 当类型是Data将在dataWatches容器中删除相关数据。
- 当类型是Any将在childWatches容器中和dataWatches容器中删除相关数据。
最后对containsWatcher方法进行分析,具体处理代码如下。
public boolean containsWatcher(String path, WatcherType type, Watcher watcher) {
boolean containsWatcher = false;
switch (type) {
case Children:
containsWatcher = this.childWatches.containsWatcher(path, watcher);
break;
case Data:
containsWatcher = this.dataWatches.containsWatcher(path, watcher);
break;
case Any:
if (this.childWatches.containsWatcher(path, watcher)) {
containsWatcher = true;
}
if (this.dataWatches.containsWatcher(path, watcher)) {
containsWatcher = true;
}
break;
}
return containsWatcher;
}
在上述代码中是根据不同观察者类型在不同容器中判断是否存在,判断细节如下。
- 当类型是Children将在childWatches容器中判断数据是否存在。
- 当类型是Data将在dataWatches容器中判断数据是否存在。
- 当类型是Any将先在childWatches容器中判断是否存在,然后在判断在dataWatches容器中是否存在。
PathTrie 分析
本节将对PathTrie类进行分析,该类主要用作于配额目录相关的操作,一般的路径是以/zookeeper/quota/xxx(可以有多级目录)/zookeeper_limits 形式出现。在该类中出现的方法有如下三种。
- 方法addPath用于添加路径。
- 方法deletePath用于删除路径。
- 方法findMaxPrefix用于寻找最大匹配前缀路径。
在PathTrie类中负责存储数据的类是TrieNode,关于该类的定义代码如下。
static class TrieNode {
final HashMap<String, TrieNode> children;
boolean property = false;
TrieNode parent = null;
}
在TrieNode类中存在三个成员变量其含义如下,
- 成员变量children用于存储子节点信息,key表示路径,value表示节点信息
- 成员变量property可以理解为是否删除。
- 成员变量parent是父节点。
加下来对addPath方法进行分析,具体处理代码如下。
public void addPath(String path) {
// 路径为空不操作
if (path == null) {
return;
}
// 切分路径得到路径的各项元素
String[] pathComponents = path.split("/");
// 创建父节点,父节点初始化时使用根节点
TrieNode parent = rootNode;
String part = null;
// 路径元素长度小于等于1抛出异常
if (pathComponents.length <= 1) {
throw new IllegalArgumentException("Invalid path " + path);
}
// 处理每个路径元素
for (int i = 1; i < pathComponents.length; i++) {
// 获取元素
part = pathComponents[i];
// 如果在父节点中不存在当前元素对应的节点则添加一个新的子节点
if (parent.getChild(part) == null) {
parent.addChild(part, new TrieNode(parent));
}
// 重新设置父节点
parent = parent.getChild(part);
}
// 父节点property属性设置
parent.setProperty(true);
}
在上述代码中核心处理流程如下。
- 判断操作路径是否为空,如果为空则不做处理。
- 将操作路径进行切分,得到路径组成元素。
- 创建父节点,父节点的初始值使用成员变量rootNode。注意:父节点是会被修改的。
- 判断第(2)步中的路径组成元素数量是否小于等于1,如果是则抛出异常。
- 循环处理路径元素,对单个路径元素进行如下操作。
- 在父节点中寻找当前路径元素对应的节点,如果不存在则向父节点中添加子节点数据。
- 修改父节点数据,修改内容为父节点中获取的子节点。
在上述处理流程中需要使用到TrieNode类中的addChild方法,具体处理代码如下。
void addChild(String childName, TrieNode node) {
synchronized (children) {
if (children.containsKey(childName)) {
return;
}
children.put(childName, node);
}
}
在上述代码中处理流程:判断当前操作节点路径是否已经在容器children中存在,如果存在则不做操作,反之则需要将数据加入到容器children中。
接下来对deletePath方法进行分析,具体处理代码如下。
public void deletePath(String path) {
// 路径为空不操作
if (path == null) {
return;
}
// 切分路径得到路径的各项元素
String[] pathComponents = path.split("/");
// 创建父节点,父节点初始化时使用根节点
TrieNode parent = rootNode;
String part = null;
// 路径元素长度小于等于1抛出异常
if (pathComponents.length <= 1) {
throw new IllegalArgumentException("Invalid path " + path);
}
// 处理每个路径元素
for (int i = 1; i < pathComponents.length; i++) {
part = pathComponents[i];
// 如果在父节点中不存在当前元素对应的节点则返回结束后续处理
if (parent.getChild(part) == null) {
//the path does not exist
return;
}
// 重新设置父节点
parent = parent.getChild(part);
LOG.info("{}", parent);
}
// 在parent节点中获取父节点,然后进行删除操作
TrieNode realParent = parent.getParent();
realParent.deleteChild(part);
}
在上述代码中核心处理流程如下。
- 判断操作路径是否为空,如果为空则不做处理。
- 将操作路径进行切分,得到路径组成元素。
- 创建父节点,父节点的初始值使用成员变量rootNode。注意:父节点是会被修改的。
- 判断第(2)步中的路径组成元素数量是否小于等于1,如果是则抛出异常。
- 循环处理路径元素,对单个路径元素进行如下操作:在父节点中寻找当前路径元素对应的节点,如果对应节点不存在则结束处理,反之则重新设置父节点,设置的数据是当前操作元素的节点。
- 在parent节点中获取父节点,然后进行删除操作。
在上述处理流程中最重要的是deleteChild方法,具体处理代码如下。
void deleteChild(String childName) {
synchronized (children) {
if (!children.containsKey(childName)) {
return;
}
TrieNode childNode = children.get(childName);
// this is the only child node.
if (childNode.getChildren().length == 1) {
childNode.setParent(null);
children.remove(childName);
} else {
childNode.setProperty(false);
}
}
}
在上述代码中主要处理流程如下。
- 判断当前操作的路径是否存在,如果不存在则不做操作。
- 在children容器中将当前操作路径对应的节点获取。如果节点的子节点数量为1则清理当前节点的父节点属性以及从children容器中移除,反之则将节点的property属性设置为false。
最后对findMaxPrefix方法进行分析,具体处理代码如下。
public String findMaxPrefix(String path) {
// 如果路径为空返回空
if (path == null) {
return null;
}
// 如果路径为/,将参数path返回
if ("/".equals(path)) {
return path;
}
// 切分路径得到路径的各项元素
String[] pathComponents = path.split("/");
// 创建父节点,父节点初始化时使用根节点
TrieNode parent = rootNode;
// 用于组装结果的容器
List<String> components = new ArrayList<String>();
// 路径元素长度小于等于1抛出异常
if (pathComponents.length <= 1) {
throw new IllegalArgumentException("Invalid path " + path);
}
int i = 1;
String part = null;
StringBuilder sb = new StringBuilder();
int lastindex = -1;
// 循环处理路径元素
while ((i < pathComponents.length)) {
// 父节点中获取路径元素对应的数据存在
if (parent.getChild(pathComponents[i]) != null) {
// 更新part数据
part = pathComponents[i];
// 覆盖父节点数据
parent = parent.getChild(part);
// 向components容器中添加数据
components.add(part);
// 如果property数据为真则将lastindex值进行重新计算
if (parent.getProperty()) {
lastindex = i - 1;
}
}
// 跳过处理
else {
break;
}
// 索引值向后操作
i++;
}
// 组装最终的响应
for (int j = 0; j < (lastindex + 1); j++) {
sb.append("/" + components.get(j));
}
return sb.toString();
}
在上述代码中主要处理流程如下。
- 判断操作路径是否为空,如果为空则返回空。
- 判断操作路径是否是根路径("/"),如果是则返回根路径("/")。
- 将操作路径进行切分,得到路径组成元素。
- 创建父节点,父节点的初始值使用成员变量rootNode。注意:父节点是会被修改的。
- 判断第(2)步中的路径组成元素数量是否小于等于1,如果是则抛出异常。
- 循环处理路径元素,单个处理流程如下。
- 判断父节点中获取路径元素对应的数据存在,如果不存在则跳过处理,反之则需要进行如下操作。
- 覆盖父节点数据。
- 向components容器中添加数据
- 如果property数据为真则将lastindex值进行重新计算,计算规则:索引值减一,注意索引初始值为1并不是从0开始 。
- 将索引值i往后移动。
- 判断父节点中获取路径元素对应的数据存在,如果不存在则跳过处理,反之则需要进行如下操作。
- 组装最终的响应。
ReferenceCountedACLCache 分析
本节将对ReferenceCountedACLCache类进行分析,在该类中主要对三个方法进行分析。
- 方法addUsage用于添加使用信息。
- 方法removeUsage用于移除使用信息。
- 方法purgeUnused用于清理信息。
- 方法convertAcls将ACL值转换为long值。
- 方法convertLong将long值转换为ACL值。
在这ReferenceCountedACLCache类中核心操作的是三个容器,容器含义见表。
| 变量名称 | 变量类型 | 变量说明 |
|---|---|---|
| longKeyMap | Map<Long, List<ACL>> | long 值和 ACL集合的映射 |
| aclKeyMap | Map<List<ACL>, Long> | ACL集合与long值的映射 |
| referenceCounter | Map<Long, AtomicLongWithEquals> | long值和计数器的映射 |
下面先对long和ACL值转换相关的方法进行分析,首先是convertAcls方法的分析,具体处理代码如下。
public synchronized Long convertAcls(List<ACL> acls) {
if (acls == null) {
return OPEN_UNSAFE_ACL_ID;
}
Long ret = aclKeyMap.get(acls);
if (ret == null) {
ret = incrementIndex();
longKeyMap.put(ret, acls);
aclKeyMap.put(acls, ret);
}
addUsage(ret);
return ret;
}
在上述代码中主要处理流程如下。
- 如果参数ACL集合为空则返回-1。
- 从容器aclKeyMap中获取ACL集合对应的long值。
- 如果long值不存在则需要将成员变量aclIndex累加一,然后将数据分别放入到容器longKeyMap,和容器aclKeyMap中。
- 执行addUsage函数,并返回long值。
接下来对convertLong方法进行分析,该方法是convertAcls方法的逆向过程,具体处理代码如下。
public synchronized List<ACL> convertLong(Long longVal) {
if (longVal == null) {
return null;
}
if (longVal == OPEN_UNSAFE_ACL_ID) {
return ZooDefs.Ids.OPEN_ACL_UNSAFE;
}
List<ACL> acls = longKeyMap.get(longVal);
if (acls == null) {
LOG.error("ERROR: ACL not available for long " + longVal);
throw new RuntimeException("Failed to fetch acls for " + longVal);
}
return acls;
}
在上述代码中主要处理流程如下。
- 如果参数longVal为空则返回空。
- 如果参数longVal为-1则返回所有ACL(所有ACL包含READ、WRITE、CREATE、DELETE和ADMIN)。
- 从容器longKeyMap中根据参数longVal获取对应的ACL信息,如果ACL信息为空则抛出异常。
下面对addUsage方法进行分析,具体处理代码如下。
public synchronized void addUsage(Long acl) {
if (acl == OPEN_UNSAFE_ACL_ID) {
return;
}
if (!longKeyMap.containsKey(acl)) {
LOG.info("Ignoring acl " + acl + " as it does not exist in the cache");
return;
}
AtomicLong count = referenceCounter.get(acl);
if (count == null) {
referenceCounter.put(acl, new AtomicLongWithEquals(1));
} else {
count.incrementAndGet();
}
}
在上述代码中核心处理流程如下。
- 判断驶入ACL值是否为-1,如果是则结束处理。
- 判断ACL值是否在longKeyMap容器中存在,如果不存在则跳过处理。
- 从计数器容器(referenceCounter)中获取ACL对应的计数器,进行累加1操作。
接下来对removeUsage方法进行分析,具体处理代码如下。
public synchronized void removeUsage(Long acl) {
if (acl == OPEN_UNSAFE_ACL_ID) {
return;
}
if (!longKeyMap.containsKey(acl)) {
LOG.info("Ignoring acl " + acl + " as it does not exist in the cache");
return;
}
long newCount = referenceCounter.get(acl).decrementAndGet();
if (newCount <= 0) {
referenceCounter.remove(acl);
aclKeyMap.remove(longKeyMap.get(acl));
longKeyMap.remove(acl);
}
}
在上述代码中核心处理流程如下。
- 判断驶入ACL值是否为-1,如果是则结束处理。
- 判断ACL值是否在longKeyMap容器中存在,如果不存在则跳过处理。
- 从计数器容器(referenceCounter)中获取ACL对应的计数器,进行累减1操作。
- 在减一操作执行后如果此时数值小于等于0则进行如下操作。
- 在计数器容器中移除ACL对应数据。
- 在aclKeyMap容器中移除ACL映射信息。
- 在longKeyMap容器中移除ACL数值对应的信息。
最后对purgeUnused方法进行分析,具体处理代码如下。
public synchronized void purgeUnused() {
Iterator<Map.Entry<Long, AtomicLongWithEquals>> refCountIter =
referenceCounter.entrySet().iterator();
while (refCountIter.hasNext()) {
Map.Entry<Long, AtomicLongWithEquals> entry = refCountIter.next();
if (entry.getValue().get() <= 0) {
Long acl = entry.getKey();
aclKeyMap.remove(longKeyMap.get(acl));
longKeyMap.remove(acl);
refCountIter.remove();
}
}
}
在上述代码中主要通过循环referenceCounter容器中的数据做出相关操作,判断元素的计数值是否小于等于0,如果是则进行如下操作。 2. 在计数器容器中移除ACL对应数据。 3. 在aclKeyMap容器中移除ACL映射信息。 4. 在longKeyMap容器中移除ACL数值对应的信息。
总结
本章对Zookeeper项目中的数据库相关内容进行分析,本章开篇对核心类ZKDatabase进行相关分析,在该类分析中引出了Zookeeper中的核心存储接口DataTree,本章对DataTree类中的关键方法做了详尽分析。此外在本章中还对Zookeeper数据库中所使用到的一些类进行相关说明。