ZooKeeper Database
This chapter begins with an analysis of the database concepts in ZooKeeper, focusing primarily on the ZKDatabase and DataTree classes.
ZKDatabase Analysis
This section analyzes the ZKDatabase class, which is the most crucial data storage unit during ZooKeeper's runtime. We'll start by examining its member variables:
| Variable Name | Variable Type | Description |
|---|---|---|
| dataTree | DataTree | Data tree structure |
| sessionsWithTimeouts | ConcurrentHashMap<Long, Integer> | Session expiration mapping table |
| snapLog | FileTxnSnapLog | Snapshot log |
| minCommittedLog | long | Minimum committed log zxid |
| maxCommittedLog | long | Maximum committed log zxid |
| committedLog | LinkedList<Proposal> | Committed log for storing proposal data |
| logLock | ReentrantReadWriteLock | Read-write lock |
| commitProposalPlaybackListener | PlayBackListener | Proposal commit event |
| snapshotSizeFactor | double | Snapshot size factor |
| initialized | boolean | Initialization status |
Through the analysis of member variables, we can understand that the ZKDatabase class stores the following data information:
- Session information
- DataTree, node data information
- Proposal information
Most methods in the ZKDatabase class are related to setting and getting data from member variables (getter and setter methods), which we won't analyze in detail. Next, we'll analyze the database loading method, loadDataBase. Here's the code:
public long loadDataBase() throws IOException {
long zxid = snapLog.restore(dataTree, sessionsWithTimeouts, commitProposalPlaybackListener);
initialized = true;
return zxid;
}
In this code, the restore method of the snapLog member variable is used to load data, and then the initialized variable is set to true. The restore method has been discussed in the log file analysis chapter, so we won't analyze it in detail here. After understanding the loadDataBase method, we need to know its specific usage scenarios, which are three:
- In the truncateLog method of this class, after truncation, a reload operation is needed. The method entry is org.apache.zookeeper.server.ZKDatabase#truncateLog.
- In the loadData method of the ZooKeeperServer class, where the outermost entry in this call line is org.apache.zookeeper.server.ServerCnxnFactory#startup(org.apache.zookeeper.server.ZooKeeperServer, boolean).
- In the start method of the QuorumPeer class.
Next, we'll analyze the getProposalsFromTxnLog method, which is used to retrieve proposal information. This method has two parameters:
- startZxid: Indicates which zxid to start searching from.
- sizeLimit: Indicates the file size limit for retrieval, used for comparison with the snapshot file size.
After understanding the parameters, let's analyze the method. Here's the code:
public Iterator<Proposal> getProposalsFromTxnLog(long startZxid,
long sizeLimit) {
// Return an empty iterator if sizeLimit is negative
if (sizeLimit < 0) {
LOG.debug("Negative size limit - retrieving proposal via txnlog is disabled");
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// Create transaction iterator
TxnIterator itr = null;
try {
// Read transaction iterator starting from startZxid
itr = snapLog.readTxnLog(startZxid, false);
// If header is not null and its zxid is greater than startZxid, close iterator and return empty iterator
if ((itr.getHeader() != null)
&& (itr.getHeader().getZxid() > startZxid)) {
LOG.warn("Unable to find proposals from txnlog for zxid: "
+ startZxid);
itr.close();
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// If sizeLimit is greater than 0
if (sizeLimit > 0) {
// Get snapshot file size
long txnSize = itr.getStorageSize();
// If file size exceeds limit, close iterator and return empty iterator
if (txnSize > sizeLimit) {
LOG.info("Txnlog size: " + txnSize + " exceeds sizeLimit: "
+ sizeLimit);
itr.close();
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
}
} catch (IOException e) {
LOG.error("Unable to read txnlog from disk", e);
try {
if (itr != null) {
itr.close();
}
} catch (IOException ioe) {
LOG.warn("Error closing file iterator", ioe);
}
return TxnLogProposalIterator.EMPTY_ITERATOR;
}
// Wrap the transaction iterator in TxnLogProposalIterator and return
return new TxnLogProposalIterator(itr);
}
The core processing flow in the above code is as follows:
- Check if sizeLimit is less than 0; if so, return an empty iterator.
- Get a transaction iterator (TxnIterator) using the snapLog member variable and startZxid parameter.
- Close the transaction iterator and return an empty iterator if the following two conditions are met:
- The header information in the transaction iterator is not null
- The zxid in the transaction iterator is greater than the current startZxid parameter.
- If startZxid is greater than 0, perform the following operations:
- Get the snapshot file size from the transaction iterator.
- If the snapshot file size exceeds the limit (sizeLimit), close the transaction iterator and return an empty iterator.
- Wrap the transaction iterator in a TxnLogProposalIterator and return it.
Next, let's analyze the log truncation method, truncateLog:
public boolean truncateLog(long zxid) throws IOException {
clear();
boolean truncated = snapLog.truncateLog(zxid);
if (!truncated) {
return false;
}
loadDataBase();
return true;
}
The processing flow in the above code is as follows:
- Use the clear method to clean up data. The cleanup items are:
- Set minCommittedLog to 0.
- Set maxCommittedLog to 0.
- Create a new DataTree object for dataTree.
- Clear the sessionsWithTimeouts container.
- Clear the committedLog container.
- Set initialized to false.
- Use FileTxnSnapLog#truncateLog method to truncate the log based on zxid.
- If the truncation result is false, return false and end processing. If true, perform a data reload operation (loadDataBase method) and return true.
DataTree Analysis
This section analyzes the DataTree class, which is the core class for simulating tree structure storage. Below is an analysis of its member variables:
| Variable Name | Variable Type | Description |
|---|---|---|
| rootZookeeper | String | "/" string |
| procZookeeper | String | "/zookeeper" string |
| procChildZookeeper | String | "zookeeper" string |
| quotaZookeeper | String | "/zookeeper/quota" string |
| quotaChildZookeeper | String | "quota" string |
| configZookeeper | String | "/zookeeper/config" string |
| configChildZookeeper | String | "config" string |
| nodes | ConcurrentHashMap<String, DataNode> | Node container, key: node path, value: data node |
| dataWatches | WatchManager | Data watch manager |
| childWatches | WatchManager | Child node watch manager |
| pTrie | PathTrie | Prefix matching tree, a utility class for managing quotas |
| ephemerals | Map<Long, HashSet<String>> | Ephemeral node set in sessions, key: session id, value: ephemeral node set |
| containers | Set<String> | All node paths |
| ttls | Set<String> | Set of nodes with expiration times |
| aclCache | ReferenceCountedACLCache | ACL cache |
| procDataNode | DataNode | "/zookeeper" node |
| quotaDataNode | DataNode | "/zookeeper/quota" node |
| lastProcessedZxid | long | Last processed zxid |
| root | DataNode | Root node |
After understanding the member variables, let's analyze the constructor. Here's the specific code:
public DataTree() {
// Set empty string to root node
nodes.put("", root);
// Set "/" to root node
nodes.put(rootZookeeper, root);
// Add "zookeeper" child node string to root node
root.addChild(procChildZookeeper);
// Set "/zookeeper" to procDataNode
nodes.put(procZookeeper, procDataNode);
// Add "quota" child node string to procDataNode
procDataNode.addChild(quotaChildZookeeper);
// Set "/zookeeper/quota" to quotaDataNode
nodes.put(quotaZookeeper, quotaDataNode);
// Add config node
addConfigNode();
}
This code initializes the following nodes:
- Root node, path: "/".
- Zookeeper node, path: "/zookeeper".
- Quota node, path: "/zookeeper/quota".
- Config node, path: "/zookeeper/config".
The constructor mainly sets up the 'nodes' variable. It initializes member variables and puts them into the container. Note the 'addChild' method, which completes the tree structure in the DataNode object, while in the 'nodes' container, it's flat.
Next, let's analyze the 'addConfigNode' method called in the constructor:
public void addConfigNode() {
// Get "/zookeeper" node
DataNode zookeeperZnode = nodes.get(procZookeeper);
// If "/zookeeper" node is not null, add "config" child node string
if (zookeeperZnode != null) {
zookeeperZnode.addChild(configChildZookeeper);
} else {
assert false : "There's no /zookeeper znode - this should never happen.";
}
// Add "/zookeeper/config" path and corresponding node data to nodes container
nodes.put(configZookeeper, new DataNode(new byte[0], -1L, new StatPersisted()));
try {
// Set ACL
setACL(configZookeeper, ZooDefs.Ids.READ_ACL_UNSAFE, -1);
} catch (KeeperException.NoNodeException e) {
assert false : "There's no " + configZookeeper +
" znode - this should never happen.";
}
}
The process in this code is as follows:
- Get the "/zookeeper" node from nodes.
- If the "/zookeeper" node is not null, add the "config" child node string to it; otherwise, assert and output.
- Add the "/zookeeper/config" path and corresponding node data to the nodes container.
- Set the ACL information for the "/zookeeper/config" node using the setACL method.
After initialization of the DataTree class without any data, the data structure looks like this:
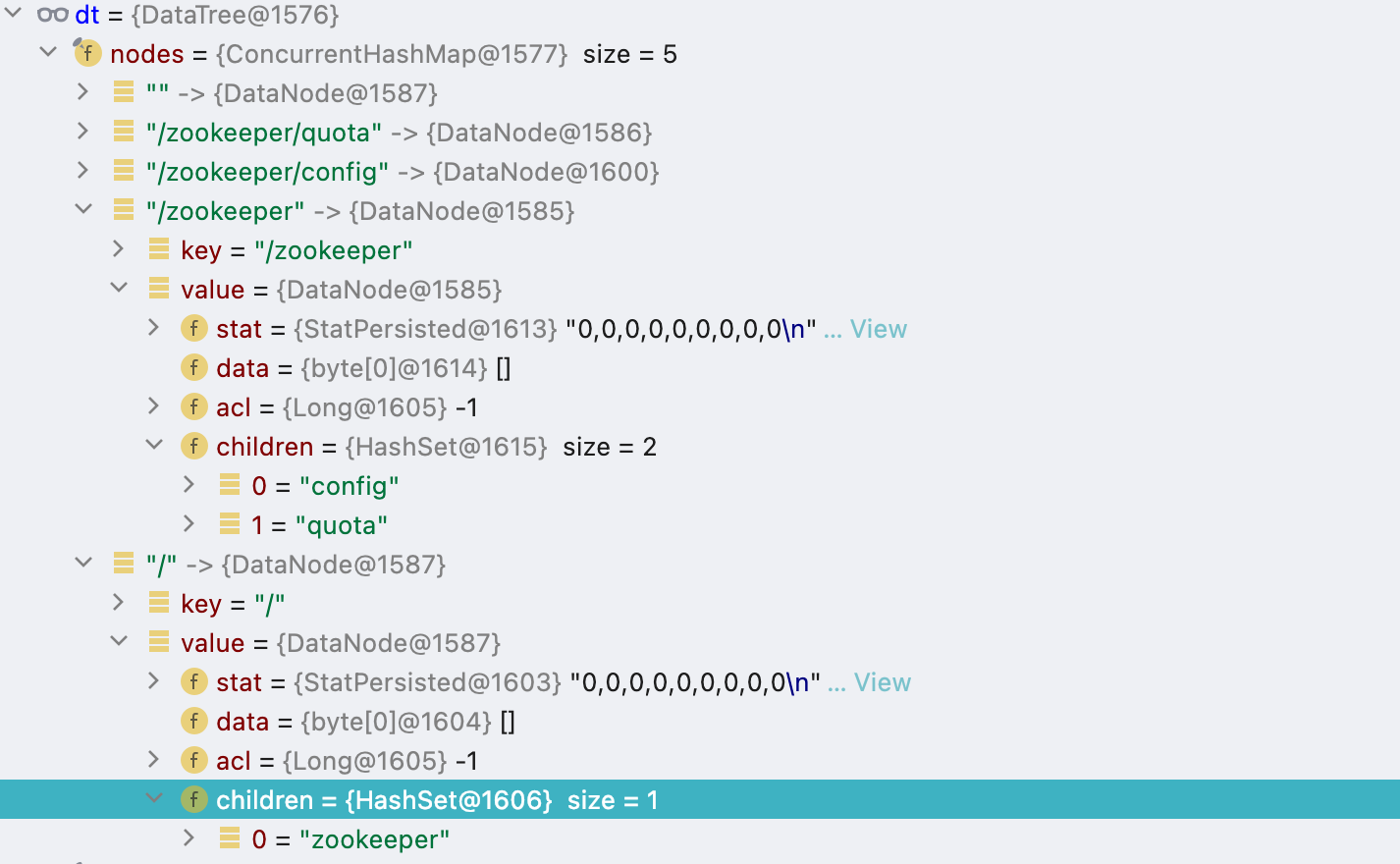
ACL Operations
This section analyzes ACL-related operations. The addConfigNode method involves setting ACL. We'll analyze both setting and getting ACL operations. First, let's look at setting ACL:
public Stat setACL(String path, List<ACL> acl, int version)
throws KeeperException.NoNodeException {
// Create stat object
Stat stat = new Stat();
// Get node data from nodes container by path
DataNode n = nodes.get(path);
// Throw exception if node data is null
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
// Remove some data from ACL cache
aclCache.removeUsage(n.acl);
// Set ACL version number to operation node
n.stat.setAversion(version);
// Convert ACL object through ACL cache and set it to data node's ACL variable
n.acl = aclCache.convertAcls(acl);
// Copy data node's stat info to newly created stat object and return
n.copyStat(stat);
return stat;
}
}
The core process in this code is:
- Create a stat object (method return value)
- Get node data from nodes container by path. If node data is null, throw an exception.
- Remove some data from ACL cache.
- Set ACL version number to operation node.
- Convert ACL object through ACL cache and set it to data node's ACL variable.
- Copy data node's stat info to newly created stat object and return.
Note that the returned object is newly created, not directly returning the data's own stat object. This is essentially to separate it from the data itself.
Next, let's analyze the getACL method for retrieving ACL data:
public List<ACL> getACL(String path, Stat stat)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
return new ArrayList<ACL>(aclCache.convertLong(n.acl));
}
}
The core process in this code is:
- Get node data from nodes container by path. If node data is null, throw an exception.
- Copy data from the data node to the parameter stat object.
- Convert the ACL data in the data node using ReferenceCountedACLCache#convertLong method.
Node Creation and Deletion Operations
This section analyzes node creation and deletion operations, mainly involving two methods: createNode and deleteNode. Let's first analyze the createNode method. Before starting the method analysis, let's explain the method parameters:
| Parameter Name | Parameter Type | Description |
|---|---|---|
| path | String | Node path |
| data | byte[] | Node data |
| acl | List<ACL> | Node permissions |
| ephemeralOwner | long | Current node owner, represented by session id. If -1, it's not an ephemeral node; otherwise, it is. |
| parentCVersion | int | Parent node's creation version number |
| zxid | long | Transaction id |
| time | long | Time |
| outputStat | Stat | Output statistics |
Now, let's analyze the method in detail. Here's the complete code:
public void createNode(final String path,
byte data[],
List<ACL> acl,
long ephemeralOwner,
int parentCVersion,
long zxid,
long time,
Stat outputStat)
throws KeeperException.NoNodeException,
KeeperException.NodeExistsException {
// Index of last slash
int lastSlash = path.lastIndexOf('/');
// Determine parent node path
String parentName = path.substring(0, lastSlash);
// Determine current operation node path
String childName = path.substring(lastSlash + 1);
// Create persistent stat object and set various data
StatPersisted stat = new StatPersisted();
stat.setCtime(time);
stat.setMtime(time);
stat.setCzxid(zxid);
stat.setMzxid(zxid);
stat.setPzxid(zxid);
stat.setVersion(0);
stat.setAversion(0);
stat.setEphemeralOwner(ephemeralOwner);
// Get parent node
DataNode parent = nodes.get(parentName);
// Throw exception if parent node doesn't exist
if (parent == null) {
throw new KeeperException.NoNodeException();
}
synchronized (parent) {
// Get parent node's child node string set
Set<String> children = parent.getChildren();
// Check if current child node is in child node string set
if (children.contains(childName)) {
throw new KeeperException.NodeExistsException();
}
// If parent node's creation version is -1, need to get from parent node and increment by 1
if (parentCVersion == -1) {
parentCVersion = parent.stat.getCversion();
parentCVersion++;
}
// Reset parent node's stat info
parent.stat.setCversion(parentCVersion);
parent.stat.setPzxid(zxid);
// Convert ACL data
Long longval = aclCache.convertAcls(acl);
// Create child node
DataNode child = new DataNode(data, longval, stat);
// Add child node path to parent node
parent.addChild(childName);
// Put data into node container
nodes.put(path, child);
// Get ephemeral owner type
EphemeralType ephemeralType = EphemeralType.get(ephemeralOwner);
// If type is CONTAINER
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
}
// If type is TTL
else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
}
// If node owner data is not 0
else if (ephemeralOwner != 0) {
// Get corresponding ephemeral node path set from ephemerals container
HashSet<String> list = ephemerals.get(ephemeralOwner);
// If ephemeral node set is null, create set and add to container; otherwise, put current operation node into ephemeral node path container
if (list == null) {
list = new HashSet<String>();
ephemerals.put(ephemeralOwner, list);
}
synchronized (list) {
list.add(path);
}
}
// If output stat object is not null, perform copy operation
if (outputStat != null) {
child.copyStat(outputStat);
}
}
// If parent node path starts with "/zookeeper/quota"
if (parentName.startsWith(quotaZookeeper)) {
// If current path is "zookeeper_limits"
if (Quotas.limitNode.equals(childName)) {
// Add to path tree
pTrie.addPath(parentName.substring(quotaZookeeper.length()));
}
// If current path is "zookeeper_stats"
if (Quotas.statNode.equals(childName)) {
// Update quota data
updateQuotaForPath(parentName
.substring(quotaZookeeper.length()));
}
}
// Maximum quota matching path
String lastPrefix = getMaxPrefixWithQuota(path);
// If maximum quota matching path is not null
if (lastPrefix != null) {
// Update counter
updateCount(lastPrefix, 1);
// Update bytes
updateBytes(lastPrefix, data == null ? 0 : data.length);
}
// Trigger data watch event
dataWatches.triggerWatch(path, Event.EventType.NodeCreated);
// Trigger child node watch event
childWatches.triggerWatch(parentName.equals("") ? "/" : parentName,
Event.EventType.NodeChildrenChanged);
}
Get Children Operation
In this section, we'll analyze the operation of getting child nodes. The specific method is getChildren, and the detailed code is as follows:
public List<String> getChildren(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
if (stat != null) {
n.copyStat(stat);
}
List<String> children = new ArrayList<String>(n.getChildren());
if (watcher != null) {
childWatches.addWatch(path, watcher);
}
return children;
}
}
The core processing flow in the above code is as follows:
- Get the data node based on the path parameter. If the data node is null, throw an exception.
- If the stat parameter is not null, copy the stat object from the data node obtained in step (1) to the stat parameter.
- Get the child node paths from the data node obtained in step (1).
- If the watcher parameter is not null, add the watcher to the data observer container.
Set Data and Get Data Operations
This section will analyze the operations of setting and getting node data, mainly involving two methods: setData and getData. Let's first analyze the setData method. The specific processing code is as follows:
public Stat setData(String path, byte data[], int version, long zxid,
long time) throws KeeperException.NoNodeException {
Stat s = new Stat();
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
byte lastdata[] = null;
synchronized (n) {
lastdata = n.data;
n.data = data;
n.stat.setMtime(time);
n.stat.setMzxid(zxid);
n.stat.setVersion(version);
n.copyStat(s);
}
String lastPrefix = getMaxPrefixWithQuota(path);
if (lastPrefix != null) {
this.updateBytes(lastPrefix, (data == null ? 0 : data.length)
- (lastdata == null ? 0 : lastdata.length));
}
dataWatches.triggerWatch(path, EventType.NodeDataChanged);
return s;
}
The core processing flow in the above code is as follows:
- Create a stat object to store the return value.
- Get the data node based on the path parameter. If the data node is null, throw an exception.
- Update the data in the data node, including:
- Data information (data).
- Statistical information (mtime, mzxid, and version).
- After updating the data information in the node, copy the data to the stat object created in step (1).
- Get the maximum quota matching path from the path parameter. If it's not null, update the bytes data.
- Trigger the watcher.
- Return the stat object.
Now, let's analyze the getData operation. The specific processing code is as follows:
public byte[] getData(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
n.copyStat(stat);
if (watcher != null) {
dataWatches.addWatch(path, watcher);
}
return n.data;
}
}
The core processing flow in the above code is as follows:
- Get the data node based on the path parameter. If the data node is null, throw an exception.
- Copy the statistical data from the data node to the stat parameter.
- If the watcher parameter is not null, add the watcher to the data observer container.
- Return the data information from the data node obtained in step (1).
Get Children Operation
This section analyzes the operation of getting child nodes. The specific method is getChildren, and the detailed code is as follows:
public List<String> getChildren(String path, Stat stat, Watcher watcher)
throws KeeperException.NoNodeException {
DataNode n = nodes.get(path);
if (n == null) {
throw new KeeperException.NoNodeException();
}
synchronized (n) {
if (stat != null) {
n.copyStat(stat);
}
List<String> children = new ArrayList<String>(n.getChildren());
if (watcher != null) {
childWatches.addWatch(path, watcher);
}
return children;
}
}
The core processing flow in the above code is as follows:
- Get the data node based on the path parameter. If the data node is null, throw an exception.
- If the stat parameter is not null, copy the stat object from the data node obtained in step (1) to the stat parameter.
- Get the child node paths from the data node obtained in step (1).
- If the watcher parameter is not null, add the watcher to the data observer container.
- Return the data from step (3).
Delete Session Operation
This section analyzes the delete session operation. The processing method is killSession, and the specific code is as follows:
void killSession(long session, long zxid) {
HashSet<String> list = ephemerals.remove(session);
if (list != null) {
for (String path : list) {
try {
deleteNode(path, zxid);
if (LOG.isDebugEnabled()) {
LOG
.debug("Deleting ephemeral node " + path
+ " for session 0x"
+ Long.toHexString(session));
}
} catch (NoNodeException e) {
LOG.warn("Ignoring NoNodeException for path " + path
+ " while removing ephemeral for dead session 0x"
+ Long.toHexString(session));
}
}
}
}
The core processing flow in the above code: Get the temporary node path set corresponding to the session from the ephemerals container. If the temporary node set is not empty, call the deleteNode method to delete the data corresponding to the temporary node path.
Serialize and Deserialize Node Operations
This section analyzes the serialize and deserialize node operations, involving the serializeNode method and the deserialize method. First, let's analyze the serializeNode method. The specific processing code is as follows:
void serializeNode(OutputArchive oa, StringBuilder path) throws IOException {
String pathString = path.toString();
DataNode node = getNode(pathString);
if (node == null) {
return;
}
String children[] = null;
DataNode nodeCopy;
synchronized (node) {
StatPersisted statCopy = new StatPersisted();
copyStatPersisted(node.stat, statCopy);
nodeCopy = new DataNode(node.data, node.acl, statCopy);
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
}
serializeNodeData(oa, pathString, nodeCopy);
path.append('/');
int off = path.length();
for (String child : children) {
path.delete(off, Integer.MAX_VALUE);
path.append(child);
serializeNode(oa, path);
}
}
The core processing flow in the above code is as follows:
- Get the data node based on the path. If the data node does not exist, skip processing.
- Create a statistics object and copy the statistical information from the data node to the statistics object.
- Create a copy of the data node object.
- Get the child node path set from the data node object.
- Serialize the path and node data to the oa variable using the serializeNodeData method.
- Loop through the child node path set to serialize them.
Next, let's analyze the deserialization method, which is the reverse process of the serializeNode method. The specific processing code is as follows:
public void deserialize(InputArchive ia, String tag) throws IOException {
aclCache.deserialize(ia);
nodes.clear();
pTrie.clear();
String path = ia.readString("path");
while (!"/".equals(path)) {
DataNode node = new DataNode();
ia.readRecord(node, "node");
nodes.put(path, node);
synchronized (node) {
aclCache.addUsage(node.acl);
}
int lastSlash = path.lastIndexOf('/');
if (lastSlash == -1) {
root = node;
}
else {
String parentPath = path.substring(0, lastSlash);
DataNode parent = nodes.get(parentPath);
if (parent == null) {
throw new IOException("Invalid Datatree, unable to find " +
"parent " + parentPath + " of path " + path);
}
parent.addChild(path.substring(lastSlash + 1));
long eowner = node.stat.getEphemeralOwner();
EphemeralType ephemeralType = EphemeralType.get(eowner);
if (ephemeralType == EphemeralType.CONTAINER) {
containers.add(path);
}
else if (ephemeralType == EphemeralType.TTL) {
ttls.add(path);
}
else if (eowner != 0) {
HashSet<String> list = ephemerals.get(eowner);
if (list == null) {
list = new HashSet<String>();
ephemerals.put(eowner, list);
}
list.add(path);
}
}
path = ia.readString("path");
}
nodes.put("/", root);
setupQuota();
aclCache.purgeUnused();
}
The core operations in the above code are as follows:
- Get path data from the input archive (variable ia).
- Loop through the path data until the path data is a slash ("/").
- Add root data to the nodes container.
- Initialize quota nodes through the setupQuota method.
- Clear unused data in the ACL cache.
The loop processing logic in step (2) above is as follows:
- Create a data node object, read node information from the input archive and put the information into the data node.
- Add data to the nodes container.
- Put the ACL data from the data node into the ACL cache.
- Get the index position of the last slash in the current operation path. If the index position is -1, set the data node object as the root node. If the index position is not -1, perform the following operations:
- Get the parent node path from the path address, extraction range: 0 to the index position of the last slash.
- Get the data node corresponding to the parent node path from the nodes container. If the data node corresponding to the parent node is null, throw an exception.
- Add child node path to the parent data node.
- Get the owner identifier of the current operation data node. If the owner identifier is of CONTAINER type, add path data to the containers container. If the owner identifier is of TTL type, add path data to the ttls container. If the owner identifier is not of CONTAINER type or TTL type, but the owner identifier is non-zero, add related data to the ephemerals container.
- Read path information from the input archive to override the path variable.
Quota Node Operations
This section analyzes the methods related to quota node operations. The specific processing method is setupQuota, and the detailed code is as follows:
private void setupQuota() {
String quotaPath = Quotas.quotaZookeeper;
DataNode node = getNode(quotaPath);
if (node == null) {
return;
}
traverseNode(quotaPath);
}
The core processing flow in the above code: Get the data node corresponding to the /zookeeper/quota path from the nodes container. If the data node does not exist, no processing is done; otherwise, process it through the traverseNode method. The traverseNode method will operate on the data under the /zookeeper/quota path. The specific processing code is as follows:
private void traverseNode(String path) {
DataNode node = getNode(path);
String children[] = null;
synchronized (node) {
Set<String> childs = node.getChildren();
children = childs.toArray(new String[childs.size()]);
}
if (children.length == 0) {
String endString = "/" + Quotas.limitNode;
if (path.endsWith(endString)) {
String realPath = path.substring(Quotas.quotaZookeeper
.length(), path.indexOf(endString));
updateQuotaForPath(realPath);
this.pTrie.addPath(realPath);
}
return;
}
for (String child : children) {
traverseNode(path + "/" + child);
}
}
The core processing flow in the above code is as follows:
- Get the data node based on the path address. The first operation retrieves the path /zookeeper/quota.
- Get the child node path set of the data node.
- If the length of the child node path set is 0, perform the following operations:
- Get the path between /zookeeper/quota/ and /zookeeper_limits, which is called the real path.
- Update the quota information related to the real path through the updateQuotaForPath method.
- Put the real path into the pTrie variable.
- Loop through the child path information from step (2) and repeat steps (1) to (4).
Watcher-related Operations
This section analyzes operations related to Watchers, involving the following three operations:
- The setWatches method is used to set watchers.
- The removeWatch method is used to remove watchers.
- The containsWatcher method is used to determine if a watcher exists.
In the ZooKeeper project, the data information observed by watchers includes three categories:
- Observing node data information, the corresponding storage container is usually named dataWatches
- Observing whether the node exists, the corresponding storage container is usually named existWatches
- Observing child node information, the corresponding storage container is usually named childWatches
Let's analyze the setWatches method. The specific processing code is as follows:
public void setWatches(long relativeZxid, List<String> dataWatches,
List<String> existWatches, List<String> childWatches,
Watcher watcher) {
for (String path : dataWatches) {
DataNode node = getNode(path);
WatchedEvent e = null;
if (node == null) {
watcher.process(new WatchedEvent(EventType.NodeDeleted,
KeeperState.SyncConnected, path));
}
else if (node.stat.getMzxid() > relativeZxid) {
watcher.process(new WatchedEvent(EventType.NodeDataChanged,
KeeperState.SyncConnected, path));
}
else {
this.dataWatches.addWatch(path, watcher);
}
}
for (String path : existWatches) {
DataNode node = getNode(path);
if (node != null) {
watcher.process(new WatchedEvent(EventType.NodeCreated,
KeeperState.SyncConnected, path));
}
else {
this.dataWatches.addWatch(path, watcher);
}
}
for (String path : childWatches) {
DataNode node = getNode(path);
if (node == null) {
watcher.process(new WatchedEvent(EventType.NodeDeleted,
KeeperState.SyncConnected, path));
}
else if (node.stat.getPzxid() > relativeZxid) {
watcher.process(new WatchedEvent(EventType.NodeChildrenChanged,
KeeperState.SyncConnected, path));
}
else {
this.childWatches.addWatch(path, watcher);
}
}
}
The main processing flow in the above code is as follows:
- Loop through dataWatches data, processing each piece of data as follows:
- Get the data node from the nodes container based on the current operation path.
- If the data node is null, pass it to the watcher parameter for event processing.
- If the mzxid in the data node is greater than the parameter zxid, pass it to the watcher parameter for event processing.
- If neither of the above two conditions is met, add the data to the dataWatches container.
- Loop through existWatches data, processing each piece of data as follows:
- Get the data node from the nodes container based on the current operation path.
- If the data node is null, pass it to the watcher parameter for event processing.
- If the data node is not null, add the data to the dataWatches container.
- Loop through childWatches data, processing each piece of data as follows:
- Get the data node from the nodes container based on the current operation path.
- If the data node is null, pass it to the watcher parameter for event processing.
- If the mzxid in the data node is greater than the parameter zxid, pass it to the watcher parameter for event processing.
- If neither of the above two conditions is met, add the data to the childWatches container.
The core of the above processing flow involves two types of operations:
- Immediately trigger the watcher for processing.
- Put the data into the watcher container for subsequent processing.
Next, let's analyze the removeWatch method. The specific processing code is as follows:
public boolean removeWatch(String path, WatcherType type, Watcher watcher) {
boolean removed = false;
switch (type) {
case Children:
removed = this.childWatches.removeWatcher(path, watcher);
break;
case Data:
removed = this.dataWatches.removeWatcher(path, watcher);
break;
case Any:
if (this.childWatches.removeWatcher(path, watcher)) {
removed = true;
}
if (this.dataWatches.removeWatcher(path, watcher)) {
removed = true;
}
break;
}
return removed;
}
The core operation in the above code is to delete data based on different watcher types. The specific deletion categories are as follows:
- When the type is Children, delete related data in the childWatches container.
- When the type is Data, delete related data in the dataWatches container.
- When the type is Any, delete related data in both the childWatches container and the dataWatches container.
Finally, let's analyze the containsWatcher method. The specific processing code is as follows:
The core processing flow in the above code is as follows:
- Check if the operation path is empty. If empty, no processing is done.
- Split the operation path to obtain the path elements.
- Create a parent node, with the initial value using the member variable rootNode. Note: The parent node will be modified.
- Check if the number of path elements from step (2) is less than or equal to 1. If so, throw an exception.
- Loop through the path elements, performing the following operation on each element: Find the node corresponding to the current path element in the parent node. If the corresponding node doesn't exist, end processing; otherwise, reset the parent node with the node of the current operation element.
- Get the parent node from the parent node, then perform the delete operation.
The most important part of the above process is the deleteChild method. The specific processing code is as follows:
void deleteChild(String childName) {
synchronized (children) {
if (!children.containsKey(childName)) {
return;
}
TrieNode childNode = children.get(childName);
// this is the only child node.
if (childNode.getChildren().length == 1) {
childNode.setParent(null);
children.remove(childName);
} else {
childNode.setProperty(false);
}
}
}
The main processing flow in the above code is as follows:
- Check if the current operation path exists. If not, no operation is performed.
- Retrieve the node corresponding to the current operation path from the children container. If the node has only one child node, clear the current node's parent property and remove it from the children container; otherwise, set the node's property attribute to false.
Finally, let's analyze the findMaxPrefix method. The specific processing code is as follows:
public String findMaxPrefix(String path) {
// Return null if the path is empty
if (path == null) {
return null;
}
// If the path is "/", return the path parameter
if ("/".equals(path)) {
return path;
}
// Split the path to get the path elements
String[] pathComponents = path.split("/");
// Create a parent node, initialized with the root node
TrieNode parent = rootNode;
// Container for assembling the result
List<String> components = new ArrayList<String>();
// Throw an exception if the path element length is less than or equal to 1
if (pathComponents.length <= 1) {
throw new IllegalArgumentException("Invalid path " + path);
}
int i = 1;
String part = null;
StringBuilder sb = new StringBuilder();
int lastindex = -1;
// Loop through the path elements
while ((i < pathComponents.length)) {
// If the data corresponding to the path element exists in the parent node
if (parent.getChild(pathComponents[i]) != null) {
// Update part data
part = pathComponents[i];
// Override parent node data
parent = parent.getChild(part);
// Add data to the components container
components.add(part);
// If the property data is true, recalculate the lastindex value
if (parent.getProperty()) {
lastindex = i - 1;
}
}
// Skip processing
else {
break;
}
// Move the index value forward
i++;
}
// Assemble the final response
for (int j = 0; j < (lastindex + 1); j++) {
sb.append("/" + components.get(j));
}
return sb.toString();
}
The main processing flow in the above code is as follows:
- Check if the operation path is empty. If empty, return null.
- Check if the operation path is the root path ("/"). If so, return the root path ("/").
- Split the operation path to obtain the path elements.
- Create a parent node, with the initial value using the member variable rootNode. Note: The parent node will be modified.
- Check if the number of path elements from step (2) is less than or equal to 1. If so, throw an exception.
- Loop through the path elements, with the following process for each:
- Check if the data corresponding to the path element exists in the parent node. If not, skip processing; otherwise, perform the following operations:
- Override the parent node data.
- Add data to the components container.
- If the property data is true, recalculate the lastindex value. Calculation rule: index value minus one, note that the initial index value is 1, not starting from 0.
- Move the index value i forward.
- Check if the data corresponding to the path element exists in the parent node. If not, skip processing; otherwise, perform the following operations:
- Assemble the final response.
ReferenceCountedACLCache Analysis
This section will analyze the ReferenceCountedACLCache class, focusing on three main methods:
- The addUsage method for adding usage information.
- The removeUsage method for removing usage information.
- The purgeUnused method for cleaning up information.
- The convertAcls method for converting ACL values to long values.
- The convertLong method for converting long values to ACL values.
In the ReferenceCountedACLCache class, the core operations involve three containers, as shown in the table below:
| Variable Name | Variable Type | Variable Description |
|---|---|---|
| longKeyMap | Map<Long, List<ACL>> | Mapping of long values to ACL collections |
| aclKeyMap | Map<List<ACL>, Long> | Mapping of ACL collections to long values |
| referenceCounter | Map<Long, AtomicLongWithEquals> | Mapping of long values to counters |
Let's first analyze the methods related to converting between long and ACL values. We'll start with the convertAcls method. The specific processing code is as follows:
public synchronized Long convertAcls(List<ACL> acls) {
if (acls == null) {
return OPEN_UNSAFE_ACL_ID;
}
Long ret = aclKeyMap.get(acls);
if (ret == null) {
ret = incrementIndex();
longKeyMap.put(ret, acls);
aclKeyMap.put(acls, ret);
}
addUsage(ret);
return ret;
}
The main processing flow in the above code is as follows:
- If the ACL collection parameter is empty, return -1.
- Get the long value corresponding to the ACL collection from the aclKeyMap container.
- If the long value doesn't exist, increment the member variable aclIndex by one, then put the data into the longKeyMap and aclKeyMap containers respectively.
- Execute the addUsage function and return the long value.
Next, let's analyze the convertLong method, which is the reverse process of the convertAcls method. The specific processing code is as follows:
public synchronized List<ACL> convertLong(Long longVal) {
if (longVal == null) {
return null;
}
if (longVal == OPEN_UNSAFE_ACL_ID) {
return ZooDefs.Ids.OPEN_ACL_UNSAFE;
}
List<ACL> acls = longKeyMap.get(longVal);
if (acls == null) {
LOG.error("ERROR: ACL not available for long " + longVal);
throw new RuntimeException("Failed to fetch acls for " + longVal);
}
return acls;
}
The main processing flow in the above code is as follows:
- If the longVal parameter is null, return null.
- If the longVal parameter is -1, return all ACLs (all ACLs include READ, WRITE, CREATE, DELETE, and ADMIN).
- Get the corresponding ACL information from the longKeyMap container based on the longVal parameter. If the ACL information is null, throw an exception.
Now let's analyze the addUsage method. The specific processing code is as follows:
public synchronized void addUsage(Long acl) {
if (acl == OPEN_UNSAFE_ACL_ID) {
return;
}
if (!longKeyMap.containsKey(acl)) {
LOG.info("Ignoring acl " + acl + " as it does not exist in the cache");
return;
}
AtomicLong count = referenceCounter.get(acl);
if (count == null) {
referenceCounter.put(acl, new AtomicLongWithEquals(1));
} else {
count.incrementAndGet();
}
}
The core processing flow in the above code is as follows:
- Check if the input ACL value is -1. If so, end processing.
- Check if the ACL value exists in the longKeyMap container. If not, skip processing.
- Get the counter corresponding to the ACL from the counter container (referenceCounter) and increment it by 1.
Next, let's analyze the removeUsage method. The specific processing code is as follows:
public synchronized void removeUsage(Long acl) {
if (acl == OPEN_UNSAFE_ACL_ID) {
return;
}
if (!longKeyMap.containsKey(acl)) {
LOG.info("Ignoring acl " + acl + " as it does not exist in the cache");
return;
}
long newCount = referenceCounter.get(acl).decrementAndGet();
if (newCount <= 0) {
referenceCounter.remove(acl);
aclKeyMap.remove(longKeyMap.get(acl));
longKeyMap.remove(acl);
}
}
The core processing flow in the above code is as follows:
- Check if the input ACL value is -1. If so, end processing.
- Check if the ACL value exists in the longKeyMap container. If not, skip processing.
- Get the counter corresponding to the ACL from the counter container (referenceCounter) and decrement it by 1.
- If the value is less than or equal to 0 after the decrement operation, perform the following operations:
- Remove the ACL corresponding data from the counter container.
- Remove the ACL mapping information from the aclKeyMap container.
- Remove the ACL value corresponding information from the longKeyMap container.
Finally, let's analyze the purgeUnused method. The specific processing code is as follows:
public synchronized void purgeUnused() {
Iterator<Map.Entry<Long, AtomicLongWithEquals>> refCountIter =
referenceCounter.entrySet().iterator();
while (refCountIter.hasNext()) {
Map.Entry<Long, AtomicLongWithEquals> entry = refCountIter.next();
if (entry.getValue().get() <= 0) {
Long acl = entry.getKey();
aclKeyMap.remove(longKeyMap.get(acl));
longKeyMap.remove(acl);
refCountIter.remove();
}
}
}
In the above code, it mainly loops through the data in the referenceCounter container and performs related operations. It checks if the count value of the element is less than or equal to 0. If so, it performs the following operations: 2. Remove the ACL corresponding data from the counter container. 3. Remove the ACL mapping information from the aclKeyMap container. 4. Remove the ACL value corresponding information from the longKeyMap container.
Summary
This chapter analyzes the database-related content in the ZooKeeper project. It begins with an analysis of the core class ZKDatabase, which introduces the core storage interface DataTree in ZooKeeper. This chapter provides a detailed analysis of the key methods in the DataTree class. Additionally, this chapter explains some classes used in the ZooKeeper database.