ZooKeeper Election Theory
This chapter introduces the foundational knowledge related to the election mechanism in the ZooKeeper project. It focuses on theoretical concepts and is summarized from the following documents:
> 1. The Part-Time Parliament paper: https://lamport.azurewebsites.net/pubs/lamport-paxos.pdf > 2. Paxos Made Simple paper: https://lamport.azurewebsites.net/pubs/paxos-simple.pdf > 3. Implementing Replicated Logs with Paxos document: https://ongardie.net/static/raft/userstudy/paxos.pdf > 4. ZooKeeper Index documentation: https://cwiki.apache.org/confluence/display/ZOOKEEPER/Index
Paxos Algorithm
The Paxos algorithm was proposed by Leslie Lamport in the 1990 paper "The Part-Time Parliament". This paper is quite abstruse and difficult to understand. Later, the original author improved and wrote the "Paxos Made Simple" paper, which is relatively easier to comprehend. This section's explanation of the Paxos algorithm also owes thanks to the author of "Implementing Replicated Logs with Paxos". The Paxos algorithm is divided into two categories: Basic Paxos and Multi Paxos. This section discusses Basic Paxos, not Multi Paxos.
- Basic Paxos: One or more nodes vote on a single variable to determine its value.
- Multi Paxos: A series of Basic Paxos instances are used to determine the values of a series of variables.
Next, we'll begin analyzing the Paxos algorithm. First, we need to clarify what problem the Paxos algorithm solves. The Paxos algorithm solves the problem of nodes reaching a common understanding of a certain value in a distributed environment. In a distributed environment with N nodes (N is recommended to be odd), the Paxos algorithm allows N nodes to quickly reach consensus on a certain value.
In the analysis of the Paxos algorithm, we need to introduce several inherent terms:
- Proposal: It consists of two parts.
- Proposal Number
- Proposal Value
- Chosen: Approved, passed, acknowledged. If a proposal value is chosen, it will be used for interaction in subsequent Paxos algorithm processes.
For convenience in describing proposals later, we'll use the notation [N,V], where N represents the proposal number and V represents the value of this proposal.
The Paxos algorithm involves three roles: Proposer, Acceptor, and Learner. Their meanings are as follows:
- Proposer: The initiator of proposals. The proposer's responsibility is to initiate proposals to the Acceptor for processing. The proposer can be understood as the party proposing an operation on a certain value.
- Acceptor: The receiver of proposals. The acceptor is the decision-maker and will vote on proposals. When a proposal is accepted by more than half of the acceptors, it is said to be chosen.
- Learner: The learner of proposals. The learner does not participate in proposal initiation or reception; it can only obtain acknowledged data (data after proposal approval) from the Proposer or Acceptor.
Typically, in a distributed environment, a node can have the following two possible roles:
- Node is only a Learner.
- Node is both a Proposer and an Acceptor.
The Paxos algorithm must also satisfy two basic requirements: Safety and Liveness. Their detailed explanations are as follows:
- Safety, with specific requirements:
- Only values proposed in a proposal can be chosen.
- If a value from a proposal has been chosen, all other participants must operate with this value.
- Liveness:
- Ensure that a value is chosen. If no value is chosen, the entire environment will be unavailable.
Regarding liveness, the Implementing Replicated Logs with Paxos document uses the following diagram to illustrate:
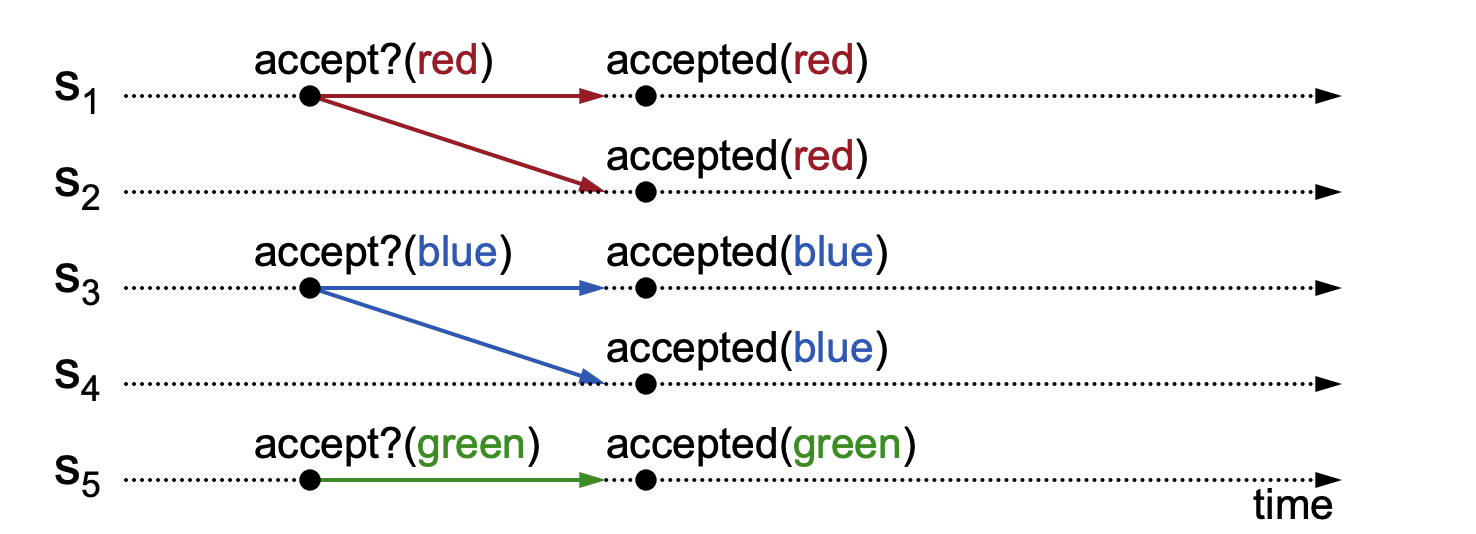
Explanation of the above diagram: In a distributed environment with 5 nodes S1, S2, S3, S4, and S5, S1, S3, and S5 receive proposals simultaneously. S1 and S2 both approve the value "red", S3 and S4 both approve "blue", and S5 approves "green". We can see that there isn't a majority (N/2+1) of nodes approving any single value among red, blue, and green, thus violating the liveness requirement of the Paxos algorithm. This phenomenon is called Split Votes. As there's no majority consensus on which value should be confirmed, the confirmation process keeps repeating, leading to an unavailable environment.
To solve the split votes problem, can we let the acceptor approve every value it receives? The Implementing Replicated Logs with Paxos document illustrates this approach with the following diagram:
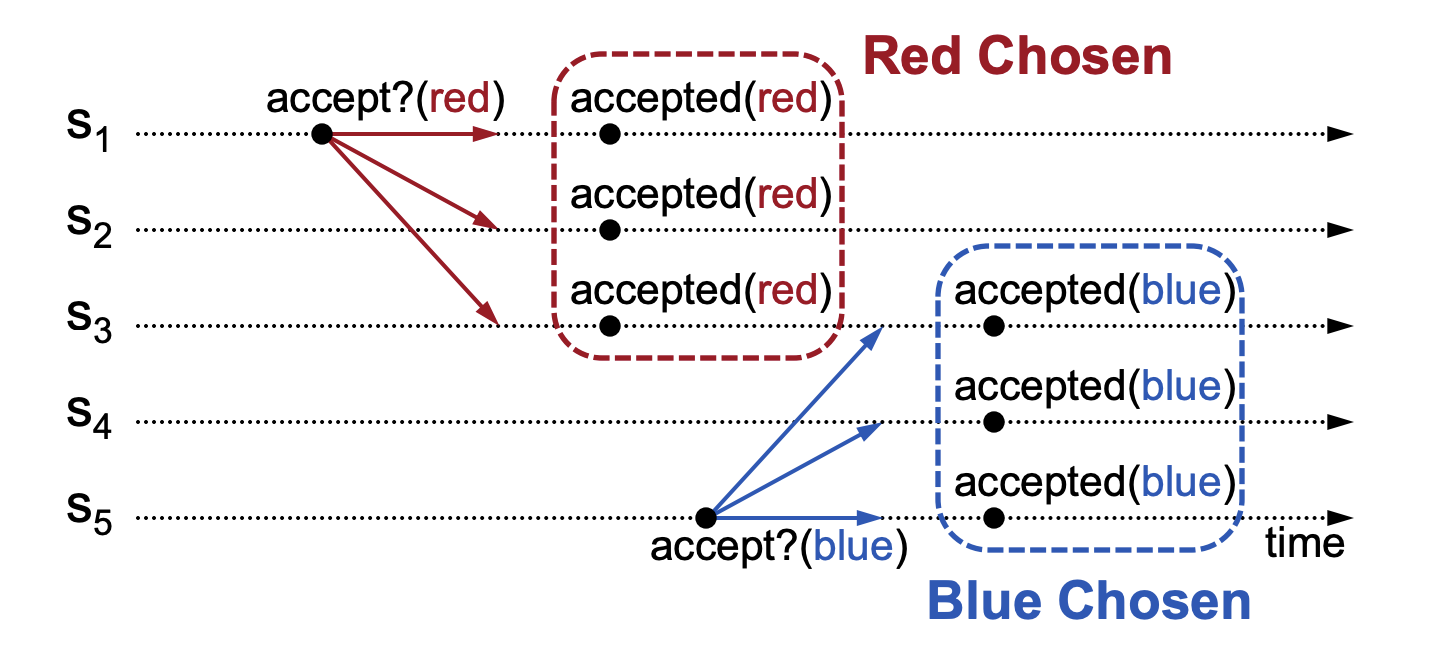
In the above diagram, we can see that node S3 has chosen both red and blue, violating the safety requirement. To address this safety issue, we can introduce a 2-phase protocol, which defines: when a value has been approved, subsequent values will be discarded unless they are identical to the currently approved value. The Implementing Replicated Logs with Paxos document illustrates this approach with the following diagram:
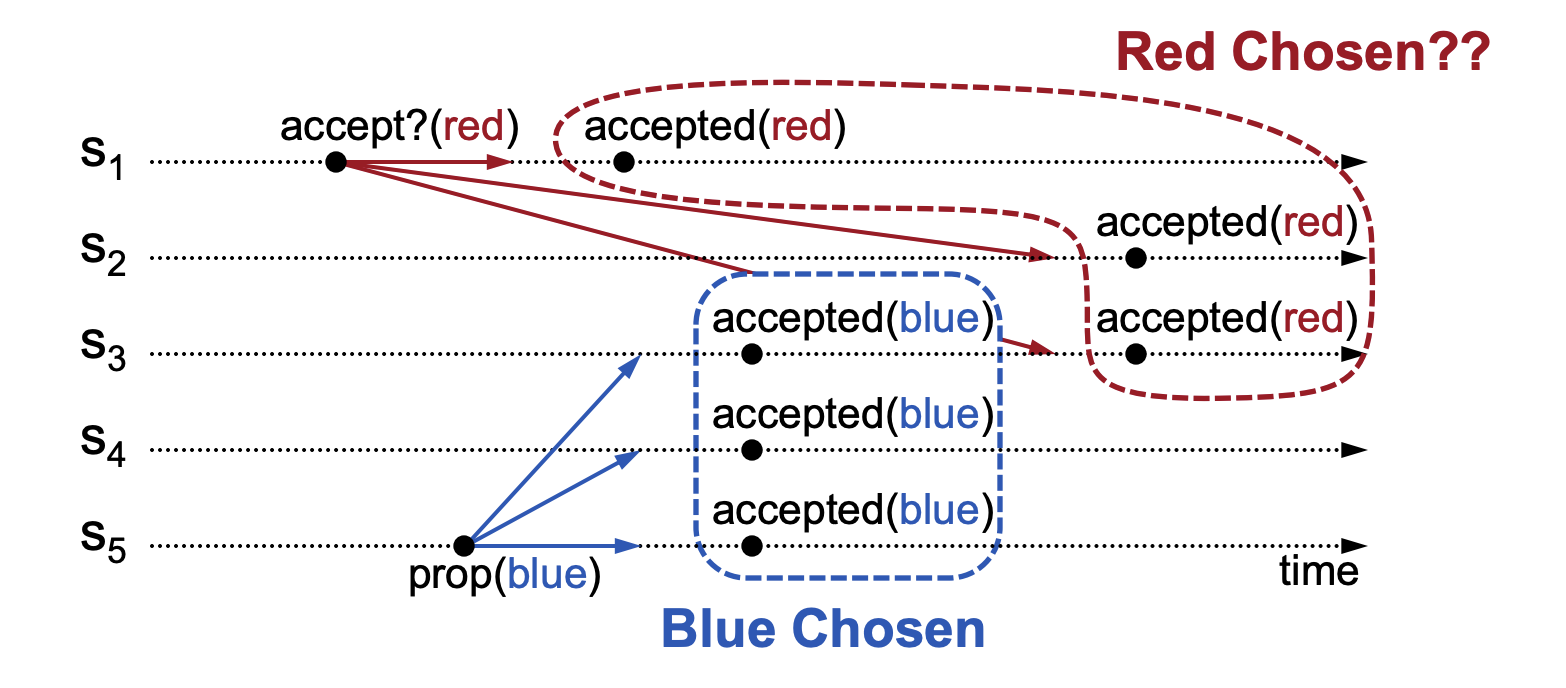
In the above diagram, node S3 first approves the value blue. Later, S3 receives a message to change the approved value to red. According to the 2-phase protocol, since the proposed value red is not the same as the previously approved value blue, it is discarded, and the approved value remains blue. Note that this approach involves sorting proposals, which requires defining sorting rules. In the Paxos algorithm, the sorting rule can use proposal numbers, defined as <Round Number, Server Id>. The proposal number consists of two parts:
- Round Number: This is an auto-incrementing integer maintained by the current node.
- Server Id: This is the service number, defined by the myid property in the zoo.cfg file in ZooKeeper.
The above describes the basic logic and requirements for reaching consensus on a value in a distributed system. The Implementing Replicated Logs with Paxos document illustrates the two-phase process with the following diagram:

The English workflow for the above diagram is as follows:
- All proposers choose a proposal number n and broadcast this proposal (Prepare(n)) to all services.
- All proposal receivers accept the proposal (Prepare(n)). If the proposal number in the received proposal is greater than the local proposal number, the local proposal number needs to be overwritten with the received proposal number, and the approved proposal number and value are returned.
- When a proposer receives approval from a majority, it broadcasts (Accept(n,value)) to all services, where n is the proposal number and value is the approved value.
- All proposal receivers check if the proposal number in the received Accept message is greater than or equal to the local proposal number. If so, they overwrite the data and return the minimum proposal number.
- Proposers no longer accept data with proposal numbers less than n. Otherwise, the entire process is repeated. If no new proposal numbers are generated, then the value has been chosen.
In the "Implementing Replicated Logs with Paxos" document, three phenomena in the Paxos algorithm are illustrated. The first phenomenon: A proposal has been chosen, meaning that more than half of the nodes have approved a certain value. New proposals must discard their values and use the chosen one, as shown in the following figure.
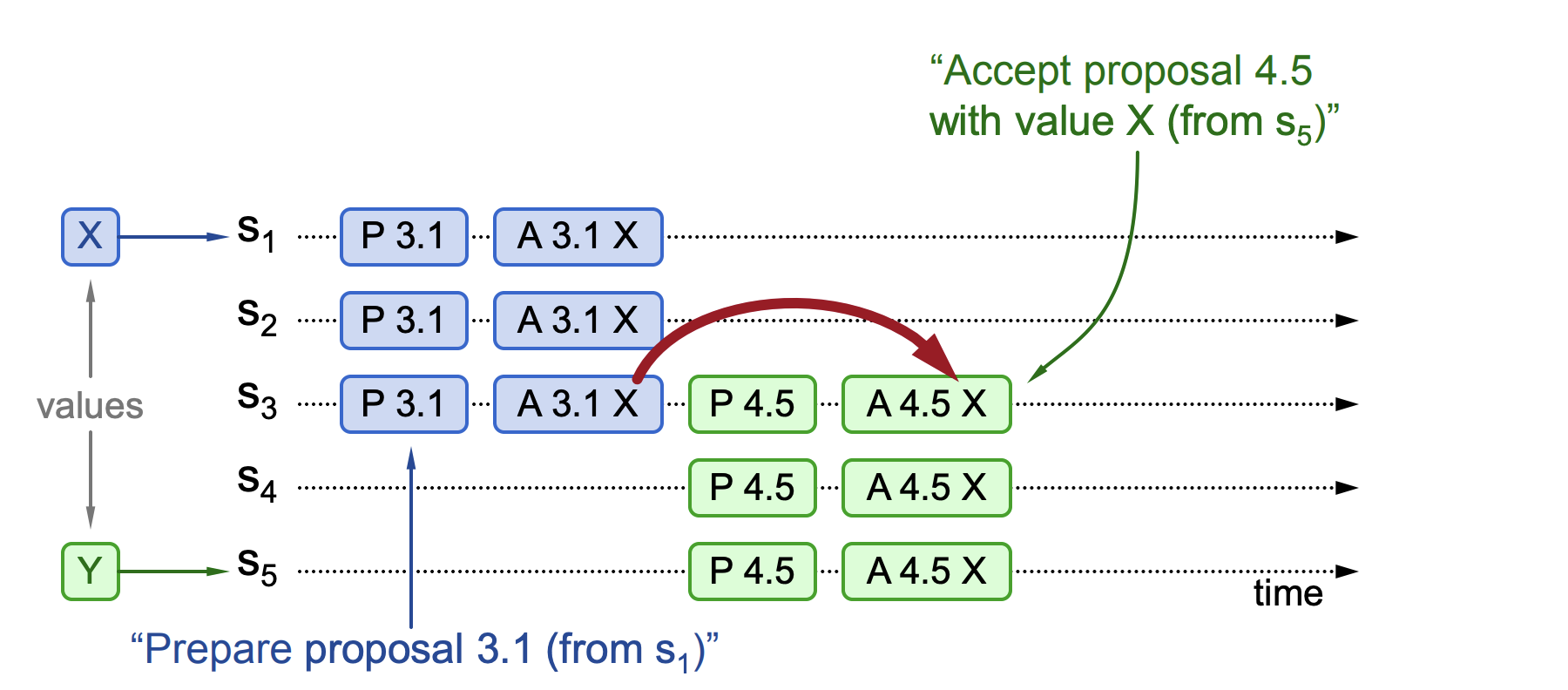
In the above diagram, there are five nodes: S1, S2, S3, S4, and S5. Node S1 initiates a proposal broadcast (proposal number 3.1, value X). It quickly gains majority approval: S1, S2, and S3 receive and approve the proposal. Then, a new proposal is received from S5 (proposal number 4.5, value Y). Assuming node S3 needs to choose between the two proposals, it will select the already approved proposal number 3.1 and set the value to X, thus abandoning the choice of Y and making S1, S2, S3, S4, and S5 approve X.
The second phenomenon: The proposal is not chosen, but proposal information is visible. This means that less than half of the nodes have approved a certain value, but the new proposal received contains this approval information, as shown in the following figure.
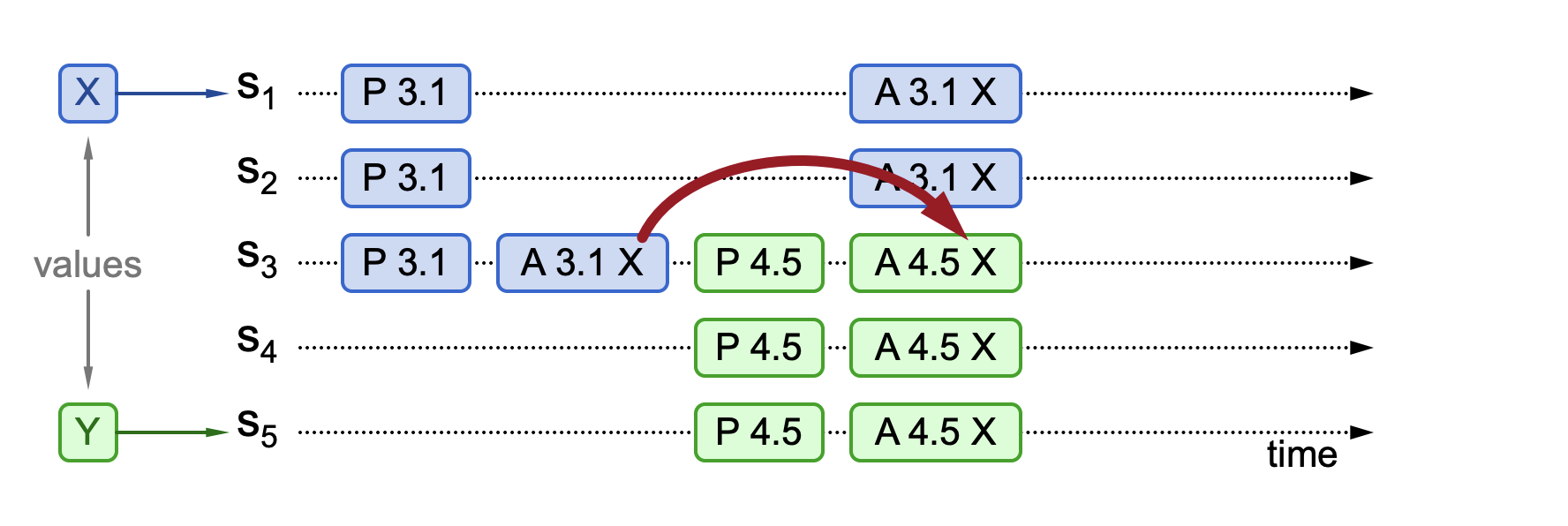
In this diagram, there are five nodes: S1, S2, S3, S4, and S5. Node S1 initiates a proposal broadcast (proposal number 3.1, value X). At this time, only a minority of nodes approve the proposal (S3 approves). Then, S5 initiates a new proposal (proposal number 4.5, value Y). S3, S4, and S5 approve proposal 4.5, but since S3 has a historically approved proposal number 3.1, it will approve the value from the previous proposal and discard the value in proposal number 4.5. Therefore, S3's approved value is X. Then, it receives approvals for proposal number 3.1 from S1 and S2, with the approved value X. At this point, value X has majority approval, reaching consensus.
The third phenomenon: The proposal is not chosen, and acceptance information is not visible. This means that less than half of the nodes have approved a certain value, and the new proposal received does not contain this approval information, as shown in the following figure.
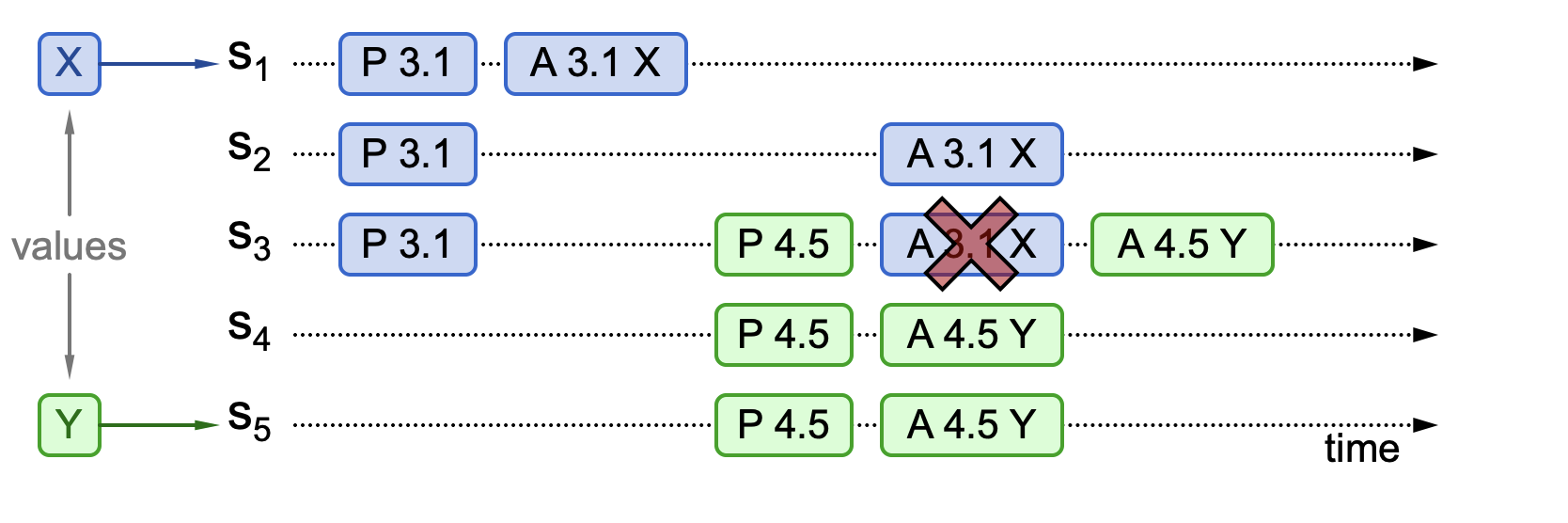
In this diagram, there are five nodes: S1, S2, S3, S4, and S5. Node S1 initiates a proposal broadcast (proposal number 3.1, value X). At this time, only a minority of nodes approve the proposal (S1 approves). Then, S5 initiates a new proposal (proposal number 4.5, value Y). The acceptance phase begins, focusing on node S3. Since S3 is processing two proposals at this time, according to the proposal sorting rules, it needs to approve the one with the larger proposal number, so its approved value is Y. S4 and S5 are also participating in the acceptance phase processing. They haven't been interfered with by proposal number 3.1, so they directly choose proposal number 4.5, with the approved value Y. At this point, the approved value Y reaches a majority, achieving consensus.
Note that based on the third phenomenon, a livelock situation may occur, as shown in the following figure.
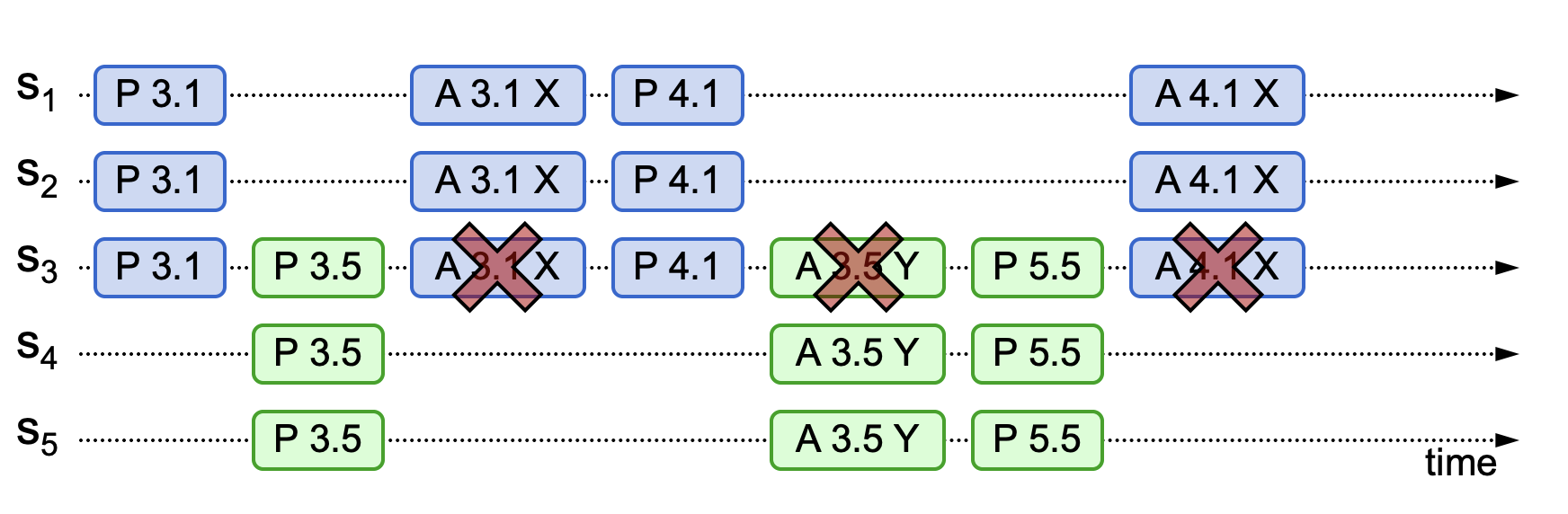
In this diagram, node S3 receives proposal number 3.5 before accepting proposal number 3.1 after initiating it. Then it receives the approval information for proposal number 3.1. Since the local proposal number is 3.5, proposal number 3.1 is smaller than 3.5 and will be discarded. This process repeats, and the entire service remains in a state of confirming sequence numbers without ever reaching majority approval, forming a livelock. The simplest way to resolve this livelock is to introduce a random timeout mechanism. This random value can allow one proposal to be submitted first.
ZAB (ZooKeeper Atomic Broadcast)
This section explains the ZAB protocol used in the ZooKeeper project. ZAB is a custom broadcast protocol used to propagate state changes in ZooKeeper. In ZAB, there are three types of roles:
- Leader: Only one leader is allowed in a ZooKeeper cluster environment. The leader is primarily responsible for three operations:
- Initiating and maintaining heartbeats with Followers and Observers.
- Handling all write requests.
- Broadcasting actual data to Followers and Observers.
- Follower: Multiple Followers are allowed in a ZooKeeper cluster environment. Followers are mainly responsible for three operations:
- Responding to the Leader's heartbeats.
- Processing read requests.
- Forwarding write requests to the Leader. Voting on write requests during processing.
- Observer: Observers are similar to Followers but do not have voting rights.
In the ZAB protocol, each node has four possible states:
- LOOKING: Initial state, typically occurring when the system first starts or after a Leader failure. Generally referred to as the election in progress state.
- FOLLOWING: Following state, only appears on Follower nodes.
- LEADING: Leading state, only appears on the Leader node.
- OBSERVING: Observing state, only appears on Observer nodes.
The ZAB protocol stipulates that all write operations must be completed through the Leader. The Leader then writes the data to its local log before broadcasting and distributing the data to Followers and Observers. If the Leader becomes unavailable, the ZAB protocol will elect a new Leader from among the Followers, a process called election. Having briefly understood the concept of election, let's explain three situations that require an election:
- Cluster initialization phase.
- When a node loses communication with the Leader during cluster operation.
- When more than half of the Followers in the cluster fail.
The ZAB protocol involves two data structure classes for communication. The first is used for initial handshakes between clients and servers, defined as follows:
class LearnerInfo {
int protocolVersion;
int serverid;
}
The second type is used for communication between Leader and Follower, with the data structure defined as follows:
class QuorumPacket {
int type;
long zxid;
buffer data;
vector<org.apache.zookeeper.data.Id> authinfo;
}
There are multiple QuorumPacket structures used in communication between Leader and Follower. The specific information is shown in the table below.
| type | type description | zxid description | data | Symbol representation | Description |
|---|---|---|---|---|---|
| UPTODATE | Represented as int type in ZooKeeper, value 12 | No zxid data | n/a | UPTODATE | Current Follower is updated and can provide service |
| TRUNC | Represented as int type in ZooKeeper, value 14 | Indicates zxid to truncate from | n/a | TRUNC(truncZxid) | Log truncation needed, rollback synchronization flag |
| SNAP | Represented as int type in ZooKeeper, value 15 | Indicates last operated zxid | n/a | SNAP | Full synchronization flag |
| PROPOSAL | Represented as int type in ZooKeeper, value 2 | Indicates zxid of proposal | Proposal content | PROPOSAL(zxid, data) | Initiate proposal |
| OBSERVERINFO | Represented as int type in ZooKeeper, value 16 | Indicates last acknowledged zxid | Leader info | OBSERVERINFO(lastZxid) | zxid acknowledged by Observer |
| NEWLEADER | Represented as int type in ZooKeeper, value 10 | e << 32, election epoch left-shifted 32 bits | n/a | NEWLEADER(e) | Acknowledge new Leader in epoch (e) |
| LEADERINFO | Represented as int type in ZooKeeper, value 17 | Indicates proposed election epoch | Protocol | LEADERINFO(e) | Propose new election epoch |
| INFORM | Represented as int type in ZooKeeper, value 8 | Indicates zxid in proposal | Protocol data | INFORM(zxid, data) | Provide data information |
| FOLLOWERINFO | Represented as int type in ZooKeeper, value 11 | Indicates accepted election epoch | Leader info | FOLLOWERINFO(acceptedEpoch) | Follower accepts election epoch |
| DIFF | Represented as int type in ZooKeeper, value 13 | Indicates Leader's last committed zxid | n/a | DIFF(lastCommittedZxid) | lastCommittedZxid is Leader's last committed zxid, differential sync flag |
| COMMIT | Represented as int type in ZooKeeper, value 4 | Indicates zxid when proposal committed | n/a | COMMIT(zxid) | All historical zxid in Follower node committed |
| ACKEPOCH | Represented as int type in ZooKeeper, value 18 | Indicates last operated zxid | Current election epoch | ACKEPOCH(lastZxid,currentEpoch) | Acknowledge current election epoch |
| ACK | Represented as int type in ZooKeeper, value 3 | Indicates ACKed zxid | n/a | ACK(zxid) | Accept historical data before current zxid |
In ZAB, Follower nodes have the following data information:
- history: Historical data information
- lastZxid: The last operated zxid
- acceptedEpoch: Accepted election epoch
- currentEpoch: Current election epoch
The ZAB protocol must satisfy the following three conditions:
- Use a best-effort leader election algorithm.
- Followers and Observers can only have one Leader at a time.
- Servers must process packets according to their accepted attributes.
Once a Leader is confirmed in the ZAB protocol (ZAB does not specify the Leader election algorithm), three phases of processing operations will be performed: the first phase creates the election epoch, the second phase synchronizes, and the third phase broadcasts.
The first phase process is as follows:
- The Leader begins accepting connections from Followers.
- Followers connect to the Leader and send FOLLOWERINFO.
- Once the Leader has a majority (2/N+1) of Follower connections, it stops accepting connections and sends LEADERINFO(e) to all Followers, where e is greater than the acceptedEpoch data in all Followers.
- When a Follower receives the LEADERINFO(e) data packet, it performs the following operations:
- If e > acceptedEpoch, the Follower sets acceptedEpoch to e and sends an ACKEPOCH(e) data packet
- If e == acceptedEpoch, the Follower does nothing
- If e < acceptedEpoch, the Follower closes the connection with the Leader and returns to election
- The Leader waits to receive ACKEPOCH data packets from the required number of Followers.
- If all Follower connections in the Leader do not meet the following conditions, the Leader will disconnect the Followers and return to election:
- Follower.currentEpoch <= Leader.currentEpoch
- Follower.currentEpoch = Leader.currentEpoch and Follower.lastZxid <= Leader.lastZxid
The second phase process is as follows:
- The Leader performs the following operations for all Followers:
- Adds the Follower to the connection list collection, used for sending processing proposals. Proposals have the following situations:
- If the Follower's zxid is far less than the Leader's zxid, it will send a SNAP data packet.
- If the Follower has transactions that the Leader chose to skip, it will send a TRUNC(zxid) data packet. zxid is the last zxid acknowledged by the Follower during the following phase.
- If the transaction sent by the Leader is missing in the Follower, it will send DIFF, and the Leader will send the missing data to the Follower.
- Sends a NEWLEADER data packet
- The Leader sends all messages that need to be processed to the Follower
- Adds the Follower to the connection list collection, used for sending processing proposals. Proposals have the following situations:
- The Follower synchronizes with the Leader, but won't make any modifications until receiving the NEWLEADER(e) data packet. Once the NEWLEADER(e) data packet is received, it updates f.currentEpoch to e from the packet, then sends an ACK(e << 32) data packet.
- Once the Leader receives ACK(e << 32) data packets from a majority of Followers, it will send an UPTODATE data packet to the Followers.
- When a Follower receives the UPTODATE data packet, it updates its state, begins accepting client requests, and starts serving clients.
- The Leader starts accepting Follower connections again, and the nextZxid variable needs to be set to (e<<32)+1.
The third phase process is as follows:
- The Leader sends a PROPOSE(zxid, data) data packet to the Followers. (zxid = nextZxid, nextZxid increments)
- Followers record the data from the PROPOSE packet and send an ACK(zxid) data packet to the Leader.
- After the Leader receives ACK data packets from a majority of Followers, it will send COMMIT(zxid) to all Followers.
Data Operations
This section will explain the data operations in ZAB (ZooKeeper Atomic Broadcast). Data operations can be divided into two types: read operations and write operations. When considering these two types of data operations in the context of ZAB, we have the following operational scenarios:
- Write operation through the Leader.
- Write operation through a Follower or Observer.
- Read operation through the Leader.
- Read operation through a Follower or Observer.
Let's first analyze the write operation through the Leader. The process flow is shown in the diagram below.
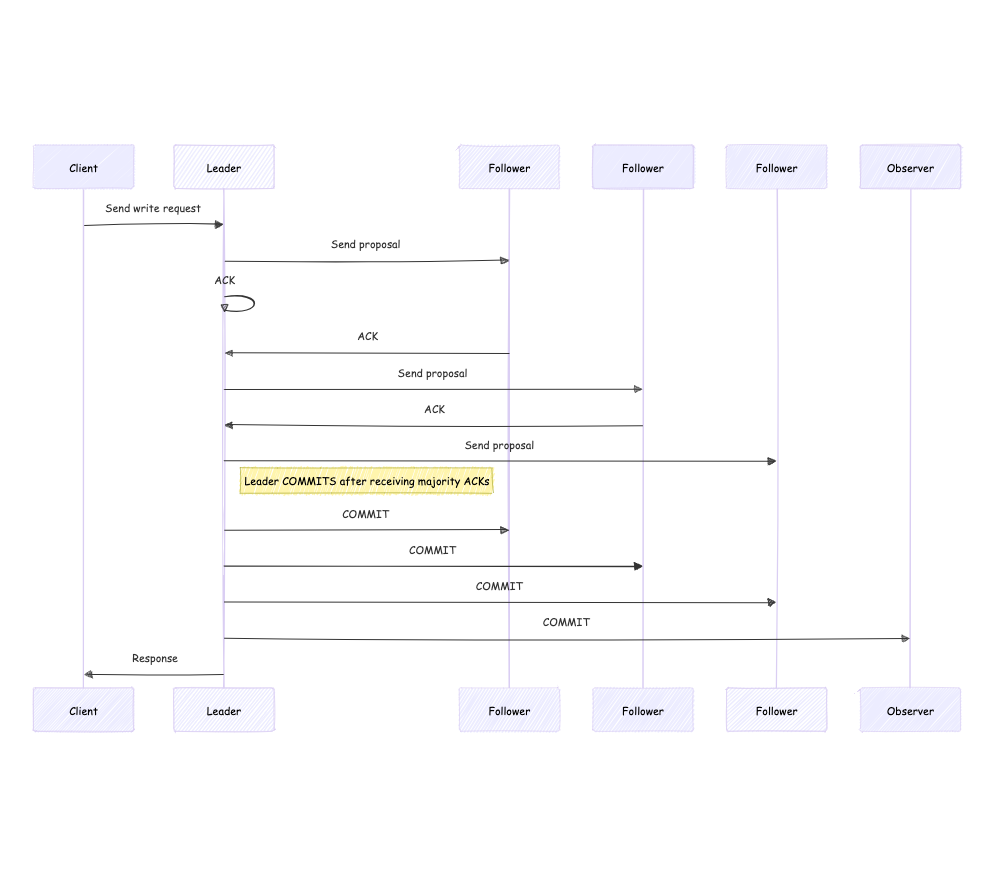
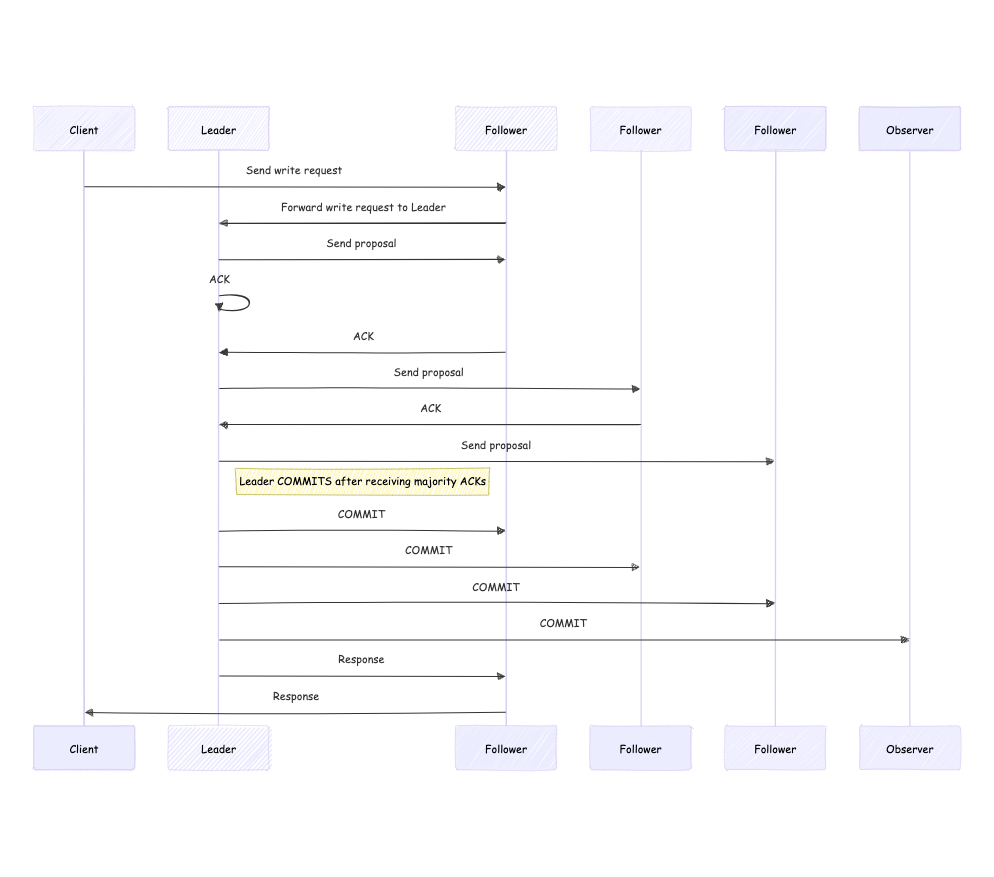
The write operation through the Leader involves the following steps:
- The client sends a write request to the Leader.
- The Leader converts the write request into a proposal and sends it to all connected Followers, waiting for ACK responses from the Followers. Note that the Leader itself carries a default ACK.
- Followers receive the proposal information and return ACKs.
- The Leader receives ACK responses from Followers. When the number of ACKs reaches a majority (2/N+1), it sends a COMMIT message to complete the data submission. Note: When receiving ACKs, it's not necessary to wait for all Followers to return ACKs; reaching half is sufficient.
- The Leader sends a response back to the client.
The write operation through the Leader involves the following steps:
- The client sends a write request to the Leader.
- The Leader converts the write request into a proposal and sends it to all connected Followers, waiting for ACK responses from the Followers. Note that the Leader itself carries a default ACK.
- Followers receive the proposal information and return ACKs.
- The Leader receives ACK responses from Followers. When the number of ACKs reaches a majority (2/N+1), it sends a COMMIT message to complete the data submission. Note: When receiving ACKs, it's not necessary to wait for all Followers to return ACKs; reaching half is sufficient.
- The Leader sends a response back to the client.
Next, let's analyze the write operation through a Follower or Observer. The main difference in this process compared to writing through the Leader is that the request first enters a Follower or Observer. Since ZAB stipulates that only the Leader can perform write operations, the request needs to be forwarded from the Follower or Observer to the Leader, and then the Leader write operation process is executed. The process flow is shown in the diagram below.
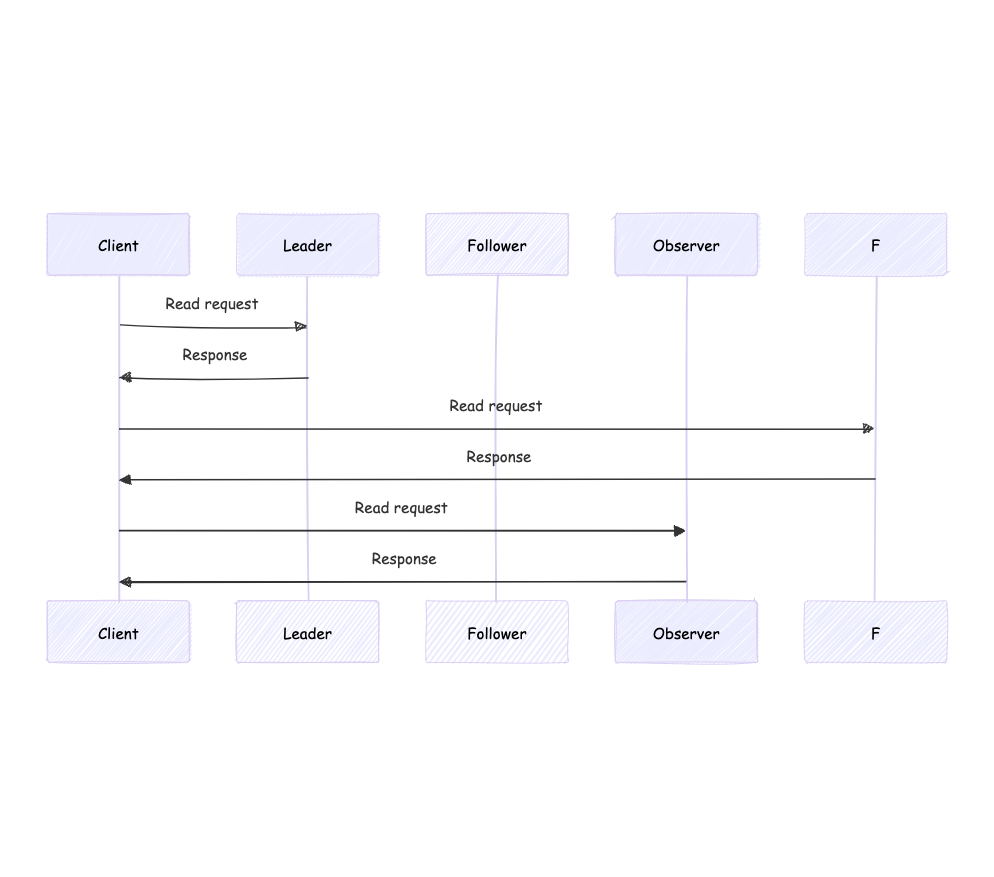
Finally, let's analyze the read operations through the Leader and through Followers or Observers. In ZAB, Leader, Followers, and Observers all allow data read operations, so they only need to read the data locally and return it to the client. The process flow is shown in the diagram below.
Election Mechanism in ZooKeeper
This section analyzes the election mechanism in the ZooKeeper project, which fills in the Leader election process in ZAB. ZooKeeper implements this using FastLeaderElection (FLE). In FLE, to become a Leader, the following conditions must be met:
- Choose the highest epoch (election cycle).
- If epochs are equal, choose the highest zxid.
- If both epoch and zxid are equal, choose the highest server_id. The server_Id is configured as the myid property in ZooKeeper's zoo.cfg.
Next, we'll explain the voting process in the election mechanism. The specific process is as follows:
- Increment the election cycle by 1, maintained by each election participant (using the logicalclock variable in the FastLeaderElection class).
- Initialize the ballot: all participating nodes vote for themselves as Leader (handled by the updateProposal method in the FastLeaderElection class).
- Send the initial ballot to all participating nodes (handled by the sendNotifications method in FastLeaderElection class, simplified process: put the ballot in the sendqueue collection, WorkerSender thread sends the message).
- Receive ballots from others, placing them in the local ballot collection. If no external ballots are received, check if there's an active connection with other cluster nodes. If so, send your own ballot; otherwise, establish a connection (simplified process: WorkerReceiver thread receives ballots from others and puts them in the recvqueue collection).
- Judge the election cycle. This involves comparing your ballot with others', and the strategy changes with the logicalclock variable. Details are as follows:
- If the external ballot's logicalclock is greater than your own, clear your ballot box, update your logicalclock to match the external ballot's, reinitialize your ballot, perform ballot comparison to decide if changes are needed, then send your ballot to other nodes.
- If the external ballot's logicalclock equals your own, proceed to ballot comparison.
- If the external ballot's logicalclock is less than your own, discard the external ballot and process the next one.
- Ballot comparison: Compare [sid (myid), zxid] with [vote id, vote zxid]. sid is your service id, zxid is your transaction id, vote id is the service id approved by the ballot, vote zxid is the external ballot's transaction id. Comparison details:
- If external ballot's logicalclock is greater, adopt all data from the external ballot.
- If logicalclocks are equal, compare zxid:
- If external zxid is greater, discard your data, update with external ballot data, and send the new ballot to other candidates.
- If external zxid is smaller, use your own ballot and send it to other candidates.
- If zxids are equal, compare sid (myid) and vote id; the larger one wins.
- Vote counting: If a majority (2/N+1) of nodes approve a ballot (note this may be an updated ballot), stop voting; otherwise, continue receiving votes.
- Update service status: If the majority voted for you, update server status to LEADING; otherwise, update to FOLLOWING.
In the entire election process, steps 4-7 continue until a Leader is elected. Now that we understand the details of the election process, we'll analyze three scenarios in the ZooKeeper cluster environment.
The first scenario is the initialization and startup phase of the ZooKeeper cluster. Since cluster elections require an odd number of services, let's simulate a ZooKeeper cluster with 3 nodes: S1 (myid=1), S2 (myid=2), and S3 (myid=3). At this initial stage, the logicalclock data for all three nodes is 0. As the election begins, the logicalclock value increments to 1. Since no data has been generated in the initialization phase, the zxid is also 0. All nodes need to initialize their ballots. For clarity and to correspond with the election process's comparison priority, we'll represent the ballot in three parts: logicalclock, sid (myid) of the recommended Leader service, and zxid. During initialization, each node votes for itself, setting sid to its own myid. The initial ballots and ballot boxes for the three nodes are as follows:
| Node | Ballot | Ballot Box |
|---|---|---|
| S1 | [1,1,0] | [1,1,0] |
| S2 | [1,2,0] | [1,2,0] |
| S3 | [1,3,0] | [1,3,0] |
After ballot initialization, nodes enter the phase of receiving others' ballots. Let's assume S1 receives ballots from S2 and S3. The following operations occur:
- Compare logicalclock: As all ballots have a logicalclock of 0, sid comparison is needed.
- Compare sid: The larger number wins.
After these operations, S3's ballot wins as it has the largest sid. S1 must change its ballot to [1,3,0] and clear its ballot box. Similarly, S2 receives ballots from S1 and S3, and S3 receives ballots from S1 and S2. After these operations, the ballots and ballot boxes are:
| Node | Ballot | Ballot Box |
|---|---|---|
| S1 | Changed [1,3,0] | Cleared due to ballot comparison |
| S2 | Changed [1,3,0] | Cleared due to ballot comparison |
| S3 | [1,3,0] | Cleared due to ballot comparison |
At this point, S1, S2, and S3 broadcast their ballots. As all ballots are [0,3,0], S3 becomes the Leader, while S1 and S2 become Followers.
The second scenario is when a Follower experiences a network partition in the cluster environment, unable to establish an effective connection with the Leader. Suppose node S1 experiences this phenomenon. S1's service status changes to LOOKING, initiating a new round of voting. S1 starts a new vote, voting for itself with ballot [2,1,0], and exchanges this information with S2 and S3. Since S2 clearly indicates S3 as the Leader, it returns ballot [2,3,3] to S1, and S3 does the same. After receiving this information, S1 performs a ballot comparison and changes its vote to [2,3,3].
The third scenario is when the Leader restarts in the cluster environment. Following the first scenario, S1 and S2 are Follower nodes, and S3 is the Leader node. When the Leader goes offline, S1 and S2 can't maintain normal communication with the Leader, triggering the election mechanism. As this is a new election, the logicalclock value is 2. The logicalclock and sid are clear, so S1 and S2's ballots are as follows:
- S1 ballot: [2,1,zxid]
- S2 ballot: [2,2,zxid]
The zxid in these two ballots may differ because during the original Leader's lifetime, only half of the Followers needed to write for a successful write operation. S1 and S2 might or might not have been part of this half, causing potential zxid differences. If the zxids are the same, the larger sid wins; if different, the larger zxid wins.
Assume S1 wins the ballot comparison and becomes the Leader. Now, S3 recovers from downtime (restarts). Upon completion, its service status is LOOKING, and it initiates an election. S3 first votes for itself with ballot [3,3,Last_Zxid], then broadcasts this information. S2, recognizing S1 as the Leader, returns ballot [3,3,zxid]. S1 receives similar information. As more than half of the nodes recognize S1 as the Leader, S3 becomes a Follower and establishes communication with S1.
Summary
This chapter focuses on theoretical aspects. It begins with an introduction to the distributed consensus algorithm Paxos, followed by an explanation of the ZAB (ZooKeeper Atomic Broadcast) algorithm specifically designed for the ZooKeeper project. After discussing ZAB, the chapter delves into the election mechanism, primarily focusing on the FastLeaderElection algorithm. It provides a detailed explanation of the core election process in the ZooKeeper project.